
Hints for a complete STRUTS Application (4)
Source code is available from arsaral(at)yahoo.com
4th Hint: selectRow and Master-Detail connection with a record structure
This program uses the Struts - iterator – selectRow facility structure in the 3rd example. The 3rd example passed only a string, this example uses a class record structure to view ina seperate screen. The next example will add new, update and delete facilities. Logging, use of message bundle and messages, imported menus etc. are excluded to make things very simple. Future examples will also handle these.
index.jsp
<BODY>
<logic:forward name="setList"></logic:forward>
</BODY>
Struts-config.xml
<struts-config>
<!-- ========== Global Forward Definitions ============================== -->
<global-forwards>
<forward name="setList" path="/setList.do"/>
</global-forwards>
<!-- ========== Action Mapping Definitions ============================== -->
<action-mappings>
<action name="setList" path="/setList"
type="com.ars.actions.SetListAction">
<forward name="success" path="/listProcess.jsp"></forward>
</action>
<action name="viewDetail" path="/viewDetail"
type="com.ars.actions.ViewDetailAction">
<forward name="success" path="/viewDetailProcess.jsp"></forward>
</action>
</action-mappings>
<message-resources parameter="arsstruts.ApplicationResources"/>
</struts-config>
As seen, first you will run index.jsp than index.jsp will run setList.do and that will run SetListAction.java.
SetListAction.java
package com.ars.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
import com.ars.beans.Person;
public final class SetListAction extends Action {
// The constructor method for this class
public SetListAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request,
HttpServletResponse response) throws Exception {
Person person = null;
HttpSession session = request.getSession();
java.util.ArrayList list = new java.util.ArrayList();
for (int i = 0; i < 13; i++) {
person = new Person();
person.setFirstName("firstName" + i);
person.setLastName("lastName" + i);
person.setCity("city" + i);
person.setCountry("country" + i);
list.add(person);
}
session.setAttribute("baseList", list);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
As seen above, SetListAction.java prepares a list named baseList and then forwards the action with “success” to struts-config.xml. struts-config.xml than runs listProcess.jsp which is given below.
listProcess.jsp
<%@ page language="java"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<logic:present name="baseList">
<table border="0" cellspacing="0" cellpadding="0" align="center" width="70%" style="border-collapse:collapse;">
<tr bgcolor="#98AFCC">
<th>First Name</th>
<th>Last Name</th>
<th>City</th>
<th>Country</th>
</tr>
<logic:iterate id="person" name="baseList">
<tr>
<td>
<bean:write name="person" property="firstName" />
</td>
<td>
<bean:write name="person" property="lastName" />
</td>
<td>
<bean:write name="person" property="city" />
</td>
<td>
<bean:write name="person" property="country" />
</td>
<td>
<html:link page="/viewDetail.do" paramName="person" paramProperty="firstName"
paramId="firstID">View</html:link>
</td>
</tr>
</logic:iterate>
</table>
</logic:present>
</body>
</html:html>
listProcess.jsp uses an html:link with pameters to run /viewDetail.do of struts-config.xml.
It passes the firstName of the selected row to ViewDetailAction.
package com.ars.actions;
import com.ars.beans.Person;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class ViewDetailAction extends Action {
// The constructor method for this class
public ViewDetailAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
String firstNameID= request.getParameter("firstID");
java.util.ArrayList list = (java.util.ArrayList) session.getAttribute("baseList");
Person personDetail = new Person();
Person personCheck = new Person();
for (Object personCheckObject : list){
personCheck = (Person) personCheckObject;
if (personCheck.getFirstName().compareTo(firstNameID) > -1 ){
personDetail.setFirstName(personCheck.getFirstName());
personDetail.setLastName(personCheck.getLastName());
personDetail.setCity(personCheck.getCity());
personDetail.setCountry(personCheck.getCountry());
break;
}
}
session.setAttribute("baseDetail",personDetail);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
viewDetailAction uses the list session object “baseList” that had been created by SetListAction to get the detail
information related to the firstID that has been passed as request param. It prepares the “baseDetail” and passes it as a session attribute to viewDetailProcess.jsp.
viewDetailProcess.jsp
<%@ page language="java"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<logic:present name="baseDetail">
<html:html>
<header>
<title>view detail page</title>
<html:base/>
</header>
<body>
<table>
<tr>
<td colspan="2">Page for Viewing the Personal Info</td>
</tr>
<tr>
<td>First Name :</td>
<td>
<bean:write name="baseDetail" property="firstName"/>
</td>
</tr>
<tr>
<td>Last Name :</td>
<td>
<bean:write name="baseDetail" property="lastName"/>
</td>
</tr>
<tr>
<td>City :</td>
<td>
<bean:write name="baseDetail" property="city"/>
</td>
</tr>
<tr>
<td>Country :</td>
<td>
<bean:write name="baseDetail" property="country"/>
</td>
</tr>
</table>
</body>
</html:html>
</logic:present>
The next hint will implement new, update and delete functions. Source and executable is available on request from arsaral( at )yahoo.com
Sunday 21 December 2008
Friday 19 December 2008
Hints for a complete STRUTS Application (3)
Hints for a complete STRUTS Application (3)
Source code is available from arsaral(at)yahoo.com
3rd Hint: selectRow and Master-Detail connection in a simple Struts example
This program uses the Struts - iterator structure in the 2nd example and builds on it the selectRow facility. It adds a hyperlink named view on each line. When you click on this hyperlink it brings the related record on a detail screen. To make it extremely simple, only a string is used in this example. Nex example will use a complete record.
selectItemList.jsp
<BODY>
<logic:forward name="selectItemList"></logic:forward>
</BODY>
</HTML>
Struts-config.xml
<global-forwards>
<forward name="selectItemList" path="/selectItemList.do"/>
</global-forwards>
<action-mappings>
<action name="selectItemList" path="/selectItemList"
type="com.masslight.actions.SetListAction">
<forward name="success" path="/selectItemProcess.jsp"></forward>
</action>
<action name="setDetail" path="/setDetail"
type="com.masslight.actions.SetDetailAction">
<forward name="success" path="/detailProcess.jsp"></forward>
</action>
</action-mappings>
As seen, first you will run selectItemList.jsp than selectItemList.jsp will run selectItemList.do and that will run SetListAction.java.
package com.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class SetListAction extends Action {
// The constructor method for this class
public SetListAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
java.util.ArrayList list = new java.util.ArrayList();
list.add("item 1");
list.add("item 2");
list.add("item 3");
session.setAttribute("baseList",list);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
As seen above, SetListAction.java prepares a list named baseList and then forwards the action with “success” to struts-config.xml. struts-config.xml than runs selectItemProcess.jsp which is given below.
selectItemProcess.jsp
<%@ page language="java"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<logic:present name="baseList">
<table border="2px" bgcolor="#CCCC99" cellspacing="1">
<logic:iterate id="iteratorItem" name="baseList">
<tr>
<td>Item Value:</td>
<td>
<bean:write name="iteratorItem"/>
</td>
<td>
<html:link page="/setDetail.do" paramName="iteratorItem"
paramId="iteratorItem">View</html:link>
</td>
</tr>
</logic:iterate>
</table>
</logic:present>
<html:submit value="Continue"/>
</body>
</html:html>
selectItemProcess.jsp uses an html:link with pameters to run /setDetail.do of struts-config.xml.
This runs SetDetailAction.
com.masslight.actions.SetDetailAction
package com.masslight.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class SetDetailAction extends Action {
// The constructor method for this class
public SetDetailAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
String detailInfo= request.getParameter("iteratorItem");
session.setAttribute("baseDetail",detailInfo);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
The ActionForward success runs the detailProcess.jsp which displays the detail, which happens to be the same word alone, for the sake of simplicity.
detailProcess.jsp
<%@ page language="java"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<bean:write name="baseDetail"/>
<br/>
<html:submit value="Continue"/>
</body>
</html:html>
Source code is available from arsaral(at)yahoo.com
3rd Hint: selectRow and Master-Detail connection in a simple Struts example
This program uses the Struts - iterator structure in the 2nd example and builds on it the selectRow facility. It adds a hyperlink named view on each line. When you click on this hyperlink it brings the related record on a detail screen. To make it extremely simple, only a string is used in this example. Nex example will use a complete record.
selectItemList.jsp
<BODY>
<logic:forward name="selectItemList"></logic:forward>
</BODY>
</HTML>
Struts-config.xml
<global-forwards>
<forward name="selectItemList" path="/selectItemList.do"/>
</global-forwards>
<action-mappings>
<action name="selectItemList" path="/selectItemList"
type="com.masslight.actions.SetListAction">
<forward name="success" path="/selectItemProcess.jsp"></forward>
</action>
<action name="setDetail" path="/setDetail"
type="com.masslight.actions.SetDetailAction">
<forward name="success" path="/detailProcess.jsp"></forward>
</action>
</action-mappings>
As seen, first you will run selectItemList.jsp than selectItemList.jsp will run selectItemList.do and that will run SetListAction.java.
package com.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class SetListAction extends Action {
// The constructor method for this class
public SetListAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
java.util.ArrayList list = new java.util.ArrayList();
list.add("item 1");
list.add("item 2");
list.add("item 3");
session.setAttribute("baseList",list);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
As seen above, SetListAction.java prepares a list named baseList and then forwards the action with “success” to struts-config.xml. struts-config.xml than runs selectItemProcess.jsp which is given below.
selectItemProcess.jsp
<%@ page language="java"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<logic:present name="baseList">
<table border="2px" bgcolor="#CCCC99" cellspacing="1">
<logic:iterate id="iteratorItem" name="baseList">
<tr>
<td>Item Value:</td>
<td>
<bean:write name="iteratorItem"/>
</td>
<td>
<html:link page="/setDetail.do" paramName="iteratorItem"
paramId="iteratorItem">View</html:link>
</td>
</tr>
</logic:iterate>
</table>
</logic:present>
<html:submit value="Continue"/>
</body>
</html:html>
selectItemProcess.jsp uses an html:link with pameters to run /setDetail.do of struts-config.xml.
This runs SetDetailAction.
com.masslight.actions.SetDetailAction
package com.masslight.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class SetDetailAction extends Action {
// The constructor method for this class
public SetDetailAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
String detailInfo= request.getParameter("iteratorItem");
session.setAttribute("baseDetail",detailInfo);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
The ActionForward success runs the detailProcess.jsp which displays the detail, which happens to be the same word alone, for the sake of simplicity.
detailProcess.jsp
<%@ page language="java"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<bean:write name="baseDetail"/>
<br/>
<html:submit value="Continue"/>
</body>
</html:html>
Hints for a complete STRUTS Application (2)
Hints for a STRUTS Application
Source code is available from arsaral(at)yahoo.com
2nd Hint: A very simple Struts Iterator Tag example
This program uses the navigation trick of the 1st HINT to prepare the simple list that will be iterated to be printed on the screen.
Index.jsp
<HTML>
…
<BODY>
<logic:forward name="setList"></logic:forward>
</BODY>
</HTML>
Struts-config.xml
<global-forwards>
<forward name="setList" path="/setList.do" />
</global-forwards>
<action-mappings>
<action name="setList" path="/setList" type="com.actions.SetListAction">
<forward name="success" path="/iterateList.jsp"></forward>
</action>
</action-mappings>
As seen, first you will run index.jsp than index.jsp will run setList.do and that will run SetListAction.java.
package com.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class SetListAction extends Action {
// The constructor method for this class
public SetListAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
java.util.ArrayList list = new java.util.ArrayList();
list.add("item 1");
list.add("item 2");
list.add("item 3");
session.setAttribute("baseList",list);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
As seen above, SetListAction.java prepares a list named baseList and then forwards the action with “success” to struts-config.xml. struts-config.xml than runs iterateList.jsp which is given below.
iterateList.jsp
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<logic:present name="baseList">
<logic:iterate id="iteratorItem" name="baseList">
Item Val: <bean:write name="iteratorItem" /><br />
</logic:iterate>
</logic:present>
<html:submit value="Continue"/>
</body>
</html:html>
iterateList.jsp very simply writes the items of the list to the screen.
Source code is available from arsaral(at)yahoo.com
2nd Hint: A very simple Struts Iterator Tag example
This program uses the navigation trick of the 1st HINT to prepare the simple list that will be iterated to be printed on the screen.
Index.jsp
<HTML>
…
<BODY>
<logic:forward name="setList"></logic:forward>
</BODY>
</HTML>
Struts-config.xml
<global-forwards>
<forward name="setList" path="/setList.do" />
</global-forwards>
<action-mappings>
<action name="setList" path="/setList" type="com.actions.SetListAction">
<forward name="success" path="/iterateList.jsp"></forward>
</action>
</action-mappings>
As seen, first you will run index.jsp than index.jsp will run setList.do and that will run SetListAction.java.
package com.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public final class SetListAction extends Action {
// The constructor method for this class
public SetListAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
HttpSession session = request.getSession();
java.util.ArrayList list = new java.util.ArrayList();
list.add("item 1");
list.add("item 2");
list.add("item 3");
session.setAttribute("baseList",list);
ActionForward forward = mapping.findForward("success");
return forward;
}
}
As seen above, SetListAction.java prepares a list named baseList and then forwards the action with “success” to struts-config.xml. struts-config.xml than runs iterateList.jsp which is given below.
iterateList.jsp
<html:html>
<header>
<title>Iterator</title>
<html:base/>
</header>
<body>
<logic:present name="baseList">
<logic:iterate id="iteratorItem" name="baseList">
Item Val: <bean:write name="iteratorItem" /><br />
</logic:iterate>
</logic:present>
<html:submit value="Continue"/>
</body>
</html:html>
iterateList.jsp very simply writes the items of the list to the screen.
Hints for a complete STRUTS Application (1)
Source code is available from arsaral(at)yahoo.com
1.st Hint: Running a program at the very beginning of a STRUTS application.
It is necessary to prepare the working environment before the standard STRUTS application begins to function through its menus and screens. Opening databases, some logging etc. may be done using this approach. Please note, I do not refer to authentication at this point. Some of these tasks may be done before the authentication or after it, depending on the implementation.
Struts-config.xml
<global-forwards>
<forward path="/init.do" name="init">
</global-forwards>
<action-mappings>
<action path="/init" name="init" type="com.actions.InitAction">
<forward path="/mainmenu.jsp" name="start">
</action>
</action-mappings>
Here, mainmenu.jsp is a jsp file residing in the WEB-INF directory. This can be any jsp which may be used
for the main menu navigation of the STRUTS application.
In the src folder of the application, there is a com and in that there is an actions folder where
InitAction.java resides:
InitAction source follows:
package com.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public class InitAction extends Action {
// The constructor method for this class
public InitAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
// Any code to prepare the environment for the new born application goes here…
ActionForward forward = mapping.findForward("start");
return forward;
}
}
As seen above, the “start” ActionForward keyword trigs the execution of the mainmenu.jsp in the
struts-config.xml.
1.st Hint: Running a program at the very beginning of a STRUTS application.
It is necessary to prepare the working environment before the standard STRUTS application begins to function through its menus and screens. Opening databases, some logging etc. may be done using this approach. Please note, I do not refer to authentication at this point. Some of these tasks may be done before the authentication or after it, depending on the implementation.
Struts-config.xml
<global-forwards>
<forward path="/init.do" name="init">
</global-forwards>
<action-mappings>
<action path="/init" name="init" type="com.actions.InitAction">
<forward path="/mainmenu.jsp" name="start">
</action>
</action-mappings>
Here, mainmenu.jsp is a jsp file residing in the WEB-INF directory. This can be any jsp which may be used
for the main menu navigation of the STRUTS application.
In the src folder of the application, there is a com and in that there is an actions folder where
InitAction.java resides:
InitAction source follows:
package com.actions;
import javax.servlet.http.*;
import org.apache.struts.action.*;
public class InitAction extends Action {
// The constructor method for this class
public InitAction() {
}
// This sets the list as a session bean
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
// Any code to prepare the environment for the new born application goes here…
ActionForward forward = mapping.findForward("start");
return forward;
}
}
As seen above, the “start” ActionForward keyword trigs the execution of the mainmenu.jsp in the
struts-config.xml.
Saturday 6 December 2008
KENDİNİ TEKRARLAYAN OLAYLARIN DOĞASI ÜZERİNE
A Mathematical Model of Chronic Events: This article discusses a mathematical model which can be used to study chronic events in large systems, specifically health and air traffic control areas.
Bu makale kronik olayları incelemek için kullanılabilecek bir matematiksel modeli tartışmaktadır. Bu tür bir model büyük sistemler ve özel olarak sağlık, hava trafik kontrolü konularında kullanılabilir. Makalenin daha temiz bir kopyasını arsaral(at)yahoo.com 'dan isteyebilirsiniz.
1. Giriş
Kendini tekrarlayan olaylar, kronik olaylar matematikte periyodik fonksiyonlar[1] şeklinde soyutlanabilirler:
f( t ) ={ f( t + k T ) k e N; t ,T e R ve T = sabit } ( Formul 1 )
Burada t zamanı, Tperiyodu yani kronik olayın iki tekrarı arasında geçen süreyi belirtir. Görüldüğü gibi fonksiyonumuz her T periyodu kadar süre geçtiğinde hep aynı değerleri almaktadır. Bu şekilde tanımlayabileceğimiz bir periyodik fonksiyona[2] ilişkin örnek bir grafik aşağıdadır.

Şekil 1
Bu şekilde t belirli bir zaman birimi cinsinden f(t) ise olayın ölçülen belirli bir niteliğinin birimi cinsinden olmalıdır. Görüldüğü gibi fonksiyon her 10 zaman birimi arayla aynı f(t) değerini almaktadır.
Kronik bir olayı modellemek için ilk olarak olaya ilişkin f(t) fonksiyonunu belirlemek gerekir.
2. Bir Olayın Matematiksel Modeli
Şekil 2
Bir olayı modellediğimiz fonksiyon olayı, olayın başlaması, olması ve bitmesini dikkate alarak soyutlamaktadır.
Buna göre olay tbaş anına kadar yoktur. Bu nedenle f( t ) fonksiyonunun değeri 0’dır. tbaş anından sonra olay vardır. Bu nedenle f( t ) 1 değerini alır, ve benzeri… Buna göre olaya ilişkin f( t ) fonksiyonu şu şekilde tanımlanabilir:
Bu makale kronik olayları incelemek için kullanılabilecek bir matematiksel modeli tartışmaktadır. Bu tür bir model büyük sistemler ve özel olarak sağlık, hava trafik kontrolü konularında kullanılabilir. Makalenin daha temiz bir kopyasını arsaral(at)yahoo.com 'dan isteyebilirsiniz.
1. Giriş
Kendini tekrarlayan olaylar, kronik olaylar matematikte periyodik fonksiyonlar[1] şeklinde soyutlanabilirler:
f( t ) ={ f( t + k T ) k e N; t ,T e R ve T = sabit } ( Formul 1 )
Burada t zamanı, Tperiyodu yani kronik olayın iki tekrarı arasında geçen süreyi belirtir. Görüldüğü gibi fonksiyonumuz her T periyodu kadar süre geçtiğinde hep aynı değerleri almaktadır. Bu şekilde tanımlayabileceğimiz bir periyodik fonksiyona[2] ilişkin örnek bir grafik aşağıdadır.
Şekil 1
Bu şekilde t belirli bir zaman birimi cinsinden f(t) ise olayın ölçülen belirli bir niteliğinin birimi cinsinden olmalıdır. Görüldüğü gibi fonksiyon her 10 zaman birimi arayla aynı f(t) değerini almaktadır.
Kronik bir olayı modellemek için ilk olarak olaya ilişkin f(t) fonksiyonunu belirlemek gerekir.
2. Bir Olayın Matematiksel Modeli
Şekil 2
Bir olayı modellediğimiz fonksiyon olayı, olayın başlaması, olması ve bitmesini dikkate alarak soyutlamaktadır.
Buna göre olay tbaş anına kadar yoktur. Bu nedenle f( t ) fonksiyonunun değeri 0’dır. tbaş anından sonra olay vardır. Bu nedenle f( t ) 1 değerini alır, ve benzeri… Buna göre olaya ilişkin f( t ) fonksiyonu şu şekilde tanımlanabilir:

Formul 2
Öte yandan birim basamak fonksiyon U( t ) şu özelliklere sahiptir[3].+fonksiyonu.JPG)
Şekil 3  Formul 3
Formul 3
Eğer birim basamak fonksiyonu U( t )’yi zaman içinde tbaş kadar ötelersek+fonksiyonu.JPG) Şekil 4
Şekil 4
Eğer tbaş kadar ötelenmiş birim basamak fonksiyonundan tson kadar ötelenmiş birim basamak fonksiyonunu çıkarırsak +-+U(t-tson)+fonksiyonu.JPG)
Şekil 5
İşte bu durumda bir olayı modelleyebileceğimiz matematiksel fonsiyonu elde etmiş oluruz.
f( t ) = U( t – tbaş ) – U( t – tson) ( Formul 4)+%3D+U(t-tba%C5%9F)+-+U(t-tson)+fonksiyonu.JPG)
Şekil 6
Bu fonksiyon matematiksel olarak şu şekilde ifade edilebilir: 
Formul 5
3. Modelin Gerçek Hayatla Karşılaştırış ve Tartılışı
U(t)’ye eşdeğer matematiksel fonksiyonlar eşik(threshold) parça parça doğrusal (piecewise linear), sigmoid ya da gaussian olabilir[4]. Eğer yakından bakarsak U( t ) şu şekli alabilir:+fonksiyonu+ger%C3%A7ek.JPG)
Şekil 7
Yani, olayın her aşamasında artma, yoğunlaşma ya da zıt yönde dalgalanmalar olabilir. Eğer bu dalgalanmalar, incelediğimiz olayın boyutu ile karşılaştırılabilir genlikte iseler, olayı tek bir olay gibi incelemek yerine birden çok olayın etkileşmesi şeklinde incelemek ya da gözlem süresini daha geniş tutmak gerekebilir.
U( t – tbaş) fonksiyonu üç fonksiyon kümeleri kümesinin bir fonksiyonu olabilir:
1- olayın olmasına ortam hazırlayan etken fonksiyonlar kümesi
2- olaya doğrudan neden olan neden fonksiyonlar kümesi
3- olayı harekete geçiren tetikleyici fonksiyonlar kümesi.
U( t – tson) fonksiyonu ise bu üç fonksiyon kümeleri kümesinin tersi işlevleri olabilir. Bu fonksiyonların matematiksel ve genel özelliklerini “Kendini Tekrarlayan Olayların Doğası Üzerine - II” adlı makalemde inceleyeceğim.
4. Kronik Bir Olayın Matematiksel Modeli
Formul 1 ve Formul 4 ‘ten periyodik bir olayı şu şekilde modelleyebiliriz:
Şekil 8
f( t ) = { U( t – tbaş + k T ) – U( t – tson + k T) k e N; t ,T e R ve T = sabit } ( Formul 6)
Bu ifade periyodik olaylar için geçerlidir. Kendini tekrar eden kronik olaylar için ise
Şekil 9
f( t ) = { U( t – tbaş + kbaş(t) Tbaş(t) ) – U( t – tson + kson(t) Tson(t))
k(t) = { kn kn e R , n e N ve n < Ksabit } ve
Tbaş(t)= { T n T n e R , n e N ve n < Ksabit } ve
Tson(t)= { T n T n e R , n e N ve n < Ksabit }
}
( Formul 7)
Tekrarlamayan olay süresi değişiklikleri tbaş tson’u zamana bağlı bir fonksiyon olarak değerlendirerek açıklamak uygun olabilir. Örneğin hava trafiğinin yoğun olduğu bir durumda kullanılan sistemlerde olabilecek bir hata yoğunluğa ilişkin olağanüstü durumun daha uzun sürmesine neden olabilir. Bu durumu tbaş ve t son’un zamana bağlı geçici bir fonksiyon değeri olarak almak gerekir.
Öte yandan, kriz durumlarının giderek ağırlaşması Tbaş (t) ve Tson (t) fonksiyonları arasındaki ilişkiyle simule edilebilir. kbaş ve kson kriz sürelerinin periyodik olarak salınımlarını incelemekte kullanılabilir.
5. Modelin Uygulamaları
5.1 Kronik olayın giderek yok oluşu
Eğer olayın tekrarlayış periyodu T çok uzarsa, yani olayın tekrarları giderek çok seyrekleşirse, Formul 6’da tbaş ve tson ‘u ihmal edip yok sayabiliriz. O zaman Formul 6 şu hali alır:
f( t ) = { U( t – k T ) – U( t – k T) k e N; t ,T e R ve T = sabit }
f( t ) = 0 ( Formul 8)
Kısacası tekrarları giderek seyrekleşen bir kronik olay giderek yok olur.
5.2 Kronik olayın giderek sıklaşması ve sürekli bir nitelik kazanışı
Eğer olayın tekrarlayış periyodu T giderek kısalıyorsa, yani olay giderek daha sık gerçekleşiyorsa, Formul 6’da k T ifadesini ihmal edip yok sayabiliriz. O zaman Formul 6 şu hali alır:
f( t ) = { U( t – tbaş ) – U( t – tson ) k e N; t ,T e R ve T = sabit } ( Formul 9)
Kısacası, formul 9 tek bir olayı modelleyen formul 4 ile aynıdır.
6. Son Değerlendiriş ve Bundan Sonrası Üzerine
Gerçek hayata bakarsak, yaptığımız modelin 5.2’de gösterdiği davranışın her zaman geçerli olmadığını görürüz. Örneğin, bazı problemler iyileşme yoluna girdiklerinde sorun belirtileri hafifleşmekle birlikte sıklaşabilir. Yani, sorun tekrarlamakla birlikte giderek daha hafif şekiller alabilir, örneğin bazı hastalıklarda. Bu durum yalnızca olayın zaman boyutunda başlangıç ve bitişlerini dikkate alan modelimizin daha da genişletilmesi gerektiğini göstermektedir. Örneğin, Formul 2’de vermiş olduğumuz fonksiyonun alanı, ( tbaş – tson ) * f( t ) yani önerdiğimiz fonksiyonun integrali gerçekleşmiş olay kapasitesi’ni ifade eder. Olay çıkma kapasitesi ise yukarıda belirttiğimiz etken, neden ve tetikleyicilere bağlıdır. Bu konuyu “Kendini Tekrarlayan Olayların Doğası Üzerine - II” adlı makalemde inceleyeceğim. Konunun havacılık ve hava trafik kontrolü açısından önemi gerçekleşmiş olay kapasitesi’nin olası kazalara ilişkin riskin hesaplanışında kullanılabilirliği olabilir.
Konunun bir diğer yönü de, kronik bir olayın nasıl algılandığıdır. Periyodik bir algılama fonksiyonunun f( t ) ile çarpımının integralinin vereceği değerler bir olayın kronikleştiğini tespit etmekte kullanılabilir. Bu algılama için geçen kontrol süresi olayı algılayışın gerektirdiği zihinsel yükün bir kısmı ile orantılıdır. Bu yöntemle aniden olay oluş durumu ya da giderek yoğun bir yükün ortaya çıkışı durumlarını gelecek makalelerimde inceleyeceğim.
REFERENCES:
.
Friday 18 July 2008
DİKKATIN DOĞASI ÜZERİNE- ON THE NATURE OF CONCENTRATION
İngilizce Türkçe Tercüme Örneği - English Turkish Translation Example for
Teknik Tercüme - Technical Translation
İTÜ’den Hocam Sn. Cevdet ACAR’a.
Bu yazım insan dikkat yeteneğinin(concentration) doğası üzerine bir dizi makalemin ilki. Gerçekten, dikkat toplamak -yoğunlaşmak (concentration) yalnız insanoğluna özgü bir özellik değil.
This is the first of a series of my articles on the nature of human concentration. Actually, concntration is not an exclusive attribute of the human-being.
Yoğunlaşmak maddenin bir özelliği. Yoğunlaşmak ‘bir noktada bir araya gelmek durumu’ olarak tanımlanır. Concentric ‘ortak bir merkezi nokta sahibi olmak’ anlamına gelir.
Concentration is an attribute of matter. Concentration is described as ‘the situation of coming together at one point.’ Concentric means ‘having a common centre.’
İnsanın yoğunlaşmak-dikkat toplamak yeteneğine gelince anlam biraz değişir. Merriam-Webster ‘ilginin bir tek nesneye yönelişi’ olarak tanımlar onu. Günlük dilde odaklanmak olarak yanlış bir şekilde kullanılır.
The meaning changes a bit when it comes to the concentration ability of the human mind. Merriam-Webster defines it as ‘direction of attention to a single object’. It is misinterpreted as focusing in the daily usage.
İnsan zihninin yeteneklerini kontrol etmek ve göstermek için kolay bir yol görsel olarak düşünmektir. Gözlerimizle bakmak açısından, dikkat toplamak – yoğunlaşmak bir tek nesneye bakmak ve diğer her şeyi bu referans noktasına göre görmektir. Odaklanmak ise bir tek şeye bakmak ve başka şeyleri hiç görmemektir.
An easy way to understand, demonstrate and control the abilities of the human mind is to think visually. In terms of looking with our eyes, concentrating means to look at something and see other things only in relation to this reference point. To focus means to look at something and not see other things at all.
Odaklanmak ilgiyi bir tek nesneye sınırlamak(örn. Bir şeyin ilgi alanı içine alınması) anlamına gelir. Yoğunlaşmak – dikkat toplamak ilginin karakterini değiştirmek ve böylece ilgi alanı içindeki nesnenin diğerlerinden bir bakıma hariç tutmaktır.
To focus means to limit your attention to a specific object(for ex. inclusion of something into attention). To concentrate means to change the character of your attention so that included thing appears in your focus on the basis of some sort of exclusion of others, so to speak.
Yoğunlaşmağı kaybetmek fakat aynı zamanda odağı korumak mümkündür. İlginizi rahatlatabilirsiniz ama, baktığınız alanın büyüklüğünü azaltabilirsiniz, örn bütün bir insan ya da bir insan yüzü. Bu rahat dikkat(relaxed attention) uygularken önemlidir.
It is possible to lose concentration but keep focus, when looking. You can relax your attention, but change the size of the area that you look at, for ex.a whole person or a face. This is important for implementing relaxed attention.
Ayrıca yoğunluğu – dikkatinizi arttırabilir ama odağınızı kaybedebilirsiniz, eğer isterseniz, bu bir parça daha karışıktır ama. Belirli hiç bir şeye bakmaz, fakat Istanbul Boğazında geniş manzarayı seyredebilirsiniz.
You may also increase your concentration but lose focus, if you like, a little bit more complex though. You may look at nothing specific, but enjoy fully the wide wiew on the coast of Istanbul Bosphorus.
Yoğunlaşmak – dikkat toplamak ve odaklanmak yetenekleri tamamen görsel değildir. Bunlar bütün algılayış, muhakeme ve motor yeteneklerinde gözlenebilirler. Benliğin vücut buluşu, varoluş duyusu zaman duyusu ile yakından ilgilidir. Varoluşumuzu, içinde bulunduğumuz andaki, yani ‘sözde şimdi - specious present’taki’ ya da şu andaki varlığımızı hissederiz.
Concentration and focusing abilities are not totally visual. These can be observed in all forms of perception, cognition, motor faculties. The embodiment of self, the sense of being is closely related with the sense of time. We feel our being, our existence at the moment we are in, namely ‘the specious present', or now.
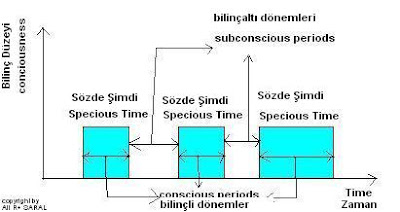
Sözde şimdi’nin uzunluğu içinde bulunduğumuz duruma göre değişir. Aynı zamanda, şimdiye ilişkin duyumuza veya kendimizi ve varlığımızı hissedişimize ait duyunun tazeleniş sıklığı değişkendir.
The length of specious present changes, according to the situation we are in. Also, the frequency of the renewal of our sense of now or feeling one’s self or being changes.
Bir şey yaparken varlığımızı her an doğrudan doğruya duymayız. Gerçekte, yaptığımız iş üzerinde yoğunlaşmak – dikkat toplamak benliğimizi hissetmek sıklığımızı azaltır. Bu aynı zamanda zaman duyusunu azaltır. Bu sıklık aynı zamanda algılayış sıklığına denk düşer. Algılayış sıklığı artarsa algılayış duyarlığı da artar.
When we are doing something we do not feel our being directly all the time. In fact concentrating on the thing we do reduces the frequency of our feeling of self. This also reduces the sense of time. This frequency also corresponds to the perception frequency. When the perception frequency increases sensitivity increases.
Sözde şimdi kavramının bu noktada başı belaya girer. Sözde şimdi toplam süresi yoğunlaşış – dikkat toplayış tarafından belirlenen, etkilenen bir algılayış süresidir.
The specious present concept is somewhat belaguered at this point. The specious present is a duration of perception, of which total duration is effected-determined by concentration.
İlgi odağın bir soyutlayışıdır. İlgi bir anda ilgilendiğimiz şeylerin sınırlarını belirler. Eğer birden çok şeyle ilgileniyorsak an uzar, yani sözde şimdi artar.
Attention is an abstraction of focus. Attention determines the limits of things we deal with at one moment. If we deal with more than one thing the length of the moment expands, so the specious present increases.
Bu niye yüksek yoğunlaşış – dikkat ile bazen zamanın çabuk geçtiğini ve bazan olduğundan uzun geçtiğini açıklar. Eğer yüksek yoğunlaşış ile tek bir iş yaparsak sözde şimdi kısalır, dolayısıyla zamanı hissetmeyiz veya olduğundan kısa hissederiz. Buna karşın, eğer yüksek yoğunlaşış ile karışık bir iş yaparsak zaman çok yavaş geçer ve zamanı olduğundan uzun hissederiz.
This explains why with high concentration sometimes, we do not feel the time that passes and sometimes we do feel it longer than it really is. If we do a single simple thing with high concentration, specious present is short, so we do not feel the time, or feel it as if shorter. On the contrary, if we do a complex thing with high concentration we feel as if the time passed is much longer than it really is.
Sözde şimdi varoluşumuzu, benliğimizi hissettiğimiz anlardır. Sözde şimdi beynin bilinçle mantıksal yorum yaptığı zamanlardır. İnsan beyninin sağlıklı çalışması bilinçli ve bilinçsiz faaliyetleri arasında ortalama dengeye dayanır.
The specious present are the moments that we feel our being, self.The specious present are the times that the brain’s cognition works consciously. Healthy functioning of human mind depends on the average balance between the conscious and subconscious activities.
Örneğin, yabancı bir dili kolaylıkla anlayabilmek için, aşırı yoğunlaşmayıp bir parça rahatlayınız, öyleki sözde şimdi sürelerinde duyduğunuz şeyler onlar arasındaki bilinçaltı sürelerinde işlenebilsin.
For example, to understand a foreign language with facility, you should not concentrate too much but you should relax a little bit, so that the things you hear at the specious durations get processed between them by your subconscious.
Karışık işlerde yüksek yoğunlukla uzun süreli çalışmak sözde şimdi sürelerimizi en yüksek sıklıkla en uzun sürede tutmamıza imkan tanıyan yetenekler geliştirmemize neden olur. Eğer kişi bu yeteneklerini idare etmek için iyi donanımlı ve eğitimli değilse, uzun süreli yüksek yoğunluklu işler insan bilinçaltını baskı altına alıp ona zarar verebilir veya algılayışı halusinasyonlar görülebilecek bir duyuş ve işitiş noktasına kadar arttırabilir. Bilinçaltının bastırılışı kaçınılmaz olarak bütün psikolojiye zarar verir ve insan beyninin bir dizi psikoz ile tepki verişine neden olabilir.
Working on complex tasks with high concentration for long durations, causes us to develop skills that enable us keep our specious presents as long as possible, with the highest frequency. If one is not well equipped and trained to handle these skills, long duration high concentration complex jobs may suppress and hurt the human subconscious or increase the perception to the point of seeing-hearing halucinations. The suppression of subconscious may inevitably hurt the whole psychology and cause the human mind to react in a series of psychosis.
Bu rezaletten uzak durmak için, çalışırken en basitinden 20 20 20 kuralını uygulayabilirsiniz. “Her 20 dakikada bir, ne yaparsanız yapın duraklayın ve 20 feet uzaktaki bir nesneye 20 saniye bakıp gözlerinizi açıp kapayın.”
In order to avoid all this mess, you should simply apply the 20 20 20 rule while working. “Every 20 minutes, pause whatever you’re doing and stare at something 20 feet away about 10-15 paces away) for 20 seconds.”
Son tahlilde, bu tür işler var olan bir çok işlerden seçmiş olduğunuz bir kaçıdır, yüksek bir dağa tırmanmağı seçebilirsiniz ya da, bir hava trafik kontrolü merkezinde mühendis ya da kontrolör olarak çalışmağı seçebilirsiniz, ya da bir cerrah olarak hizmet etmeği seçebilirsiniz. Tamamen size bağlı…
The bottom line is, this type of jobs are one of many choices, you may choose to climb a high mountain or serve at an air traffic control center as an engineer or air traffic controller, or choose to serve as a surgeon. It is up to you.
Sunday 3 February 2008
Is it Possible to translate heavy technical subjects to Turkish?
There will be a note written here about my recent efforts to translate relatively heavy and complex software texts to Turkish... Comments on if it is possible to translate critical technical texts such as a nuclear reactor's operation manuals etc. to the Turkish language? Is it meaningful? Is it safe?
Kind regards.
Kind regards.
Karşılaştırmalı Ingilizce Türkçe Teknik Çeviri Örneği
Ali Rıza SARAL(1)
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1.4 Bir Borudan Okuyuş (Reading from a Pipe)
Bir borudan veri almak isteyen bir süreç, kendi dosya tanımlayıcısı olarak borunun okuyucu kanalı ile ilişkilendirilmiş tanımlayıcıyı belirleyerek bir oku() (read( )) sistem çağrısı çıkarır. Sonuç olarak, çekirdek, dosya işlem tablosunda uygun bir dosya nesnesi ile ilişkilendirilmiş bir oku (read) metodunu başlatır. Bir boru durumunda, oku (read) metodu için oku_boru_dişl (read_pipe_fops) tablosundaki bir girdi boru_oku() (pipe_read( )) fonksiyonuna işaret eder. A process wishing to get data from a pipe issues a read( ) system call, specifying as its file descriptor the descriptor associated with the pipe's read channel. The kernel ends up invoking the read method found in the file operation table associated with the proper file object. In the case of a pipe, the entry for the read method in the read_pipe_fops table points to the pipe_read( ) function.
boru_oku() (pipe_read( )) fonksiyonu çok ilişilidir, çünkü POSIX standardı borunun okuyuş işlemlerine bir çok şart koşmuştur. Tablo 18-2 boru uzunluğu p olan(okunacak boru arabölgesindeki byteların sayısı) bir borudan n byte rica eden, oku() (read( )) sistem çağrısının umulan davranışını gösterir. Okuyuş işleminin tıkanmasız(nonblocking) olabileceğine dikkat ediniz: bu durumda, var olan bütün bytelar kullanıcı adres boşluğuna[3] kopyalanır kopyalanmaz
tamamlanır. Ayrıca, yalnız eğer boru boş ise ve borunun yazıcı kanalı ile ilişkilendirilmiş dosya nesnesini o anda hiçbir süreç kullanmıyor ise oku() (read( )) sistem çağrısı tarafından değer döndürülür.
The pipe_read( ) function is quite involved, since the POSIX standard specifies several requirements for the pipe's read operations. Table 18-2 illustrates the expected behavior of a read( ) system call that requests n bytes from a pipe having a pipe size (number of bytes in the pipe buffer yet to be read) equal to p. Notice that the read operation can be nonblocking: in this case, it completes as soon as all available bytes (even none) have been copied into the user address space.[3] Notice also that the value is returned by the read( ) system call only if the pipe is empty and no process is currently using the file object associated with the pipe's write channel.
[3] Tıkanmasız işlemler genellikle aç() (open( )) sistem çağrısı içinde O_TIKANMASIZ (O_NONBLOCK) bayrağını belirleyerek talep edilir. Bu yöntem açılamadıkları için borulara geçerli değildir; bir süreç yine de karşı düşen dosya tanımlayıcı üzerinde bir dkntl() (fcntl( )) sistem çağrısı yaparak tıkanmasız bir işlem yapılmasını şart koşabilir.
[3] Nonblocking operations are usually requested by specifying the O_NONBLOCK flag in the open( ) system call. This method does not
work for pipes, since they cannot be opened; a process can, however, require a nonblocking operation on a pipe by issuing a fcntl( ) system
call on the corresponding file descriptor.
Tablo 18-2. Bir Borudan Byte’ların Okunuşu (Reading n Bytes from a Pipe)
Fonksiyon aşağıdaki işlemleri icra eder:
1. idüğüm(inode)'ün i_boy (i_size) alanına depolanmış olan boru boyunun 0 olup olmadığını belirler. Bu durumda, fonksiyonun geri dönüşünün zorunluluğunu veya başka bir süreç boruya yazı yazışını beklerken tıkanmasının zorunlu olup olmadığını belirler(Bakınız Tablo 18-2).
The function performs the following operations:
1. Determines if the pipe size, which is stored into the inode's i_size field, is 0. In this case, determines if the function must return or if the process must be blocked while waiting until another process writes some data in the pipe (see Table 18-2).
G/Ç işleminin türü (tıkanarak ya da tıkanmasız) olacağı dosya nesnesinin d_bayraklar (f_flags) alanının O_TIKANMASIZ (O_NONBLOCK) bayrağı tarafından belirlenir. Eğer gerekirse, o andaki süreci, boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının bekle(wait) alanının işaret ettiği bekleyiş kuyruğuna soktukup sonra da askıya almak için kesilebilir_bekle_durumunda() (interruptible_sleep_on()) fonksiyonunu başlatır.
The type of I/O operation (blocking or nonblocking) is specified by the O_NONBLOCK flag in the f_flags field of the file object. If necessary, invokes the interruptible_sleep_on() function to suspend the current process after having inserted it in the wait queue to
which the wait field of the pipe_inode_info data structure points.
2. boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının kilit (lock) alanını sınar. Eğer boş değil ise,
başka bir süreç o anda boruya erişmektedir; bu durumda, ya o anki süreci askıya alır ya da okuyuş işleminin tipine göre (tıkanmasız ya da tıkayıcılı) sistem çağrısını sona erdirir.
3. lock alanını arttırır.
4. Borunun arabölgesinden kullanıcı adres boşluğuna istenen sayıda (ya da elde var olan bytelar kadar olanı, eğer arabölge çok küçük ise) byte’ı kopyalar.
5. lock alanını azaltır.
6. Borunun bekleyiş kuyruğundaki bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
7. Kullanıcı adres boşluğuna kopyalanmış olan byte’ların sayısını geri döndürür.
2. Checks the lock field of the pipe_inode_info data structure. If it is not null, another process is currently accessing the pipe; in this case, either suspends the current process or immediately terminates the system call, depending on the type of read operation (blocking or nonblocking).
3. Increments the lock field.
4. Copies the requested number of bytes (or the number of available bytes, if the buffer size is too small) from the pipe's buffer to the user address space.
5. Decrements the lock field.
6. Invokes wake_up_interruptible( ) to wake up all processes sleeping on the pipe's wait queue.
7. Returns the number of bytes copied into the user address space.
18.1.5 Boruya yazış (Writing into a Pipe)
Bir boruya veri koymak dileyen bir süreç, kendi dosya tanımlayıcısı olarak borunun yazıcı kanalı ile ilişkili tanımlayıcıyı kendi dosya tanımlayıcısı olarak belirleyerek, bir yaz() (write( )) system çağrısı çıkarır. Çekirdek bu isteği uygun dosya nesnesinin yaz (write) yöntemini başlatarak tatmin eder; yaz_boru_dişl() (write_pipe_fops) tablosunda karşı düşen girdi boru_yaz() (pipe_write( )) fonksiyonuna işaret eder. Tablo 18-3, POSIX standardına göre, arabölgesinde u (unused) kullanılmamış byte’ı olan bir borunun içine n byte yazmak isteyen bir yaz (write( )) sistem çağrısının davranışını canlandırmaktadır.
A process wishing to put data into a pipe issues a write( ) system call, specifying as its file descriptor the descriptor associated with the pipe's write channel. The kernel satisfies this request by invoking the write method of the proper file object; the corresponding entry in the write_pipe_fops table points to the pipe_write( ) function. Table 18-3 illustrates the behavior, specified by the POSIX standard, of a write( ) system call that requested to write n bytes into a pipe having u unused bytes in its buffer.
Standart özellikle küçük sayıda bytela ilgili yazıcı işlemlerin otomatik olarak ifa edilişini zorunlu kılar. Daha doğrusu, eğer iki ya da daha çok süreç boruya eş zamanlı yazıyorsalar, 4096’dan daha az (boru arabölgesi boyu) byte ile ilgili herhangi bir yazıcı işlem aynı boruya başka süreçler tarafından yapılan yazıcı işlemler ile içiçe geçirilmeden(interleave) bitmek zorundadır. Yine de, 4096 byte’tan daha uzun yazıcı işlemler gayrı-atomik olabilirler ve çağırıcı sürecin uyutuluşunu zorunlu kılabilirler.
In particular, the standard requires that write operations involving a small number of bytes must be automatically executed.
More precisely, if two or more processes are concurrently writing into a pipe, any write operation involving fewer than 4096 bytes (the pipe buffer size) must finish without being interleaved with write operations of other processes to the same pipe.
However, write operations involving more than 4096 bytes may be nonatomic and may also force the calling process to sleep.
Table 18-3. Bir Boruya n tane byte’ın yazılışı
Dahası, eğer bir borunun okuyucu süreci yoksa (yani idüğüm nesnesinin readers alanı 0 değerine sahipse) o boruya yazıcı bütün işlemler başarısız olmalıdır. O durumda, çekirdek yazıcı sürece bir -EPIPE hata kodu ile, bir SIGPIPE işareti gönderir, bu ise tanıdık “Kırık Boru” mesajına yol açar.
Moreover, any write operation to a pipe must fail if the pipe does not have a reading process (that is, if the readers field of the pipe's inode object has the value 0). In that case, the kernel sends a SIGPIPE signal to the writing process and terminates the write( ) system call with the -EPIPE error code, which usually leads to the familiar "Broken pipe" message.
pipe_write( ) fonksiyonu aşağıdaki işlemleri icra eder:
1. Borunun en azından bir okuyucu süreci olduğunu sınar. Eğer değilse, şuanki (current) sürece BORUİŞA (SIGPIPE) işaretini gönderir ve bir -EBORU (-EPIPE) değerini geri döndürür.
2. Borunun idüğümünün (inode) sys_write( ) fonksiyonu tarafından ayrılmış, i_sem semaforunu serbest bırakır ve aynı düğümün the i_atomik_yaz() (i_atomic_write) semaforunu ayırır. [4]
The pipe_write( ) function performs the following operations:
1. Checks whether the pipe has at least one reading process. If not, sends a SIGPIPE signal to the current process and return an -EPIPE value.
2. Releases the i_sem semaphore of the pipe's inode, which was acquired by the sys_write( ) function, and acquires the i_atomic_write semaphore of the same node. [4]
[4] i_sem semaforu çok sayıda sürecin bir dosya üzerinde yazış işlemleri başlatışını önler, ve dolayısıyla boru üzerinde de.
[4] The i_sem semaphore prevents multiple processes from starting write operations on a file, and thus on the pipe
3. Yazılacak byteların sayısının borunun arabölge boyu içinde olup olmadığını kontrol eder:
a. Eğer öyle ise, yazış işlemi atomik olmak zorundadır. Dolayısıyla, arabölgenin yazılacak bütün byteları depolayabilecek yeterli serbest boşluğa sahip olduğunu kontrol eder.
b. Eğer byteların sayısı arabölge boyundan daha büyükse, bir parça serbest boşluk olduğu sürece işlem başlar. Dolayısıyla en azından 1 byte boş yer olduğunu sınar.
3. Checks whether the number of bytes to be written is within the pipe's buffer size:
a.If so, the write operation must be atomic. Therefore, checks whether the buffer has enough free space to store all bytes to be written.
b. If the number of bytes is greater than the buffer size, the operation can start as long as there is any free space at all. Therefore, checks for at least 1 free byte.
4. Eğer arabölge yeterli serbest boşluğa sahip değilse ve yazıcı işlem tıkayıcıysa, şu andaki süreci borunun bekleyiş kuyruğuna sokar ve borudan bir miktar veri okununcaya kadar onu askıya alır. i_atomik_yaz() (i_atomic_write) semaforun serbest bırakılmadığının farkına varınız, dolayısıyla başka hiçbir süreç boru üstünde yazıcı bir işlem başlatamaz. Eğer yazıcı işlem tıkanmasız ise, -ETEKRAR (-EAGAIN) hata kodunu geri döndürür.
4. If the buffer does not have enough free space and the write operation is blocking, inserts the current process into the pipe's wait queue and suspends it until some data is read from the pipe. Notice that the i_atomic_write semaphore is not released, so no other process can start a write operation on the buffer. If the write operation is nonblocking, returns the -EAGAIN error code.
5. pipe_inode_info veri yapısının lock alanını sınar. Eğer boş değilse, bir başka süreç o anda boruyu okuyordur, dolayısıyla ya o anki süreci askıya alır ya da yazış işleminin tıkayıcı veya tımasız oluşuna bağlı olarak yazışı hemen sona erdirir.
6. kilit (lock) alanını arttırır.
7. İstenen sayıda byte’i (eğer boru boyu çok kısa ise serbest byte sayısı kadarını) kullanıcı adres boşluğundan borunun arabölgesine taşır.
8. Eğer hala yazılışı gereken bytelar var ise 4. adıma gider.
9. İstenen bütün veri yazıldıktan sonra, kilit (lock) alanını azaltır.
10. Borunun bekleyiş kuyruğunda bekleyen bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
11. i_atomic_write semaforu serbest bırakır ve i_sem semaforunu bağlar (böylece sys_write( ) ikincisini kolaylıkla serbest bırakabilir).
12. Borunun arabölgesine yazılan byteların sayısını geri döndürür.
5. Checks the lock field of the pipe_inode_info data structure. If it is not null, another process is currently reading the pipe, so either suspends the current process or immediately terminates the write depending on whether the write operation is blocking or nonblocking.
6. Increments the lock field.
7. Copies the requested number of bytes (or the number of free bytes if the pipe size is too small) from the user address space to the pipe's buffer.
8. If there are bytes yet to be written, goes to step 4.
9. After all requested data is written, decrements the lock field.
10. Invokes wake_up_interruptible( ) to wake up all processes sleeping on the pipe's wait queue.
11. Releases the i_atomic_write semaphore and acquires the i_sem semaphore (so that sys_write( ) can safely release the latter).
12. Returns the number of bytes written into the pipe's buffer.
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1.4 Bir Borudan Okuyuş (Reading from a Pipe)
Bir borudan veri almak isteyen bir süreç, kendi dosya tanımlayıcısı olarak borunun okuyucu kanalı ile ilişkilendirilmiş tanımlayıcıyı belirleyerek bir oku() (read( )) sistem çağrısı çıkarır. Sonuç olarak, çekirdek, dosya işlem tablosunda uygun bir dosya nesnesi ile ilişkilendirilmiş bir oku (read) metodunu başlatır. Bir boru durumunda, oku (read) metodu için oku_boru_dişl (read_pipe_fops) tablosundaki bir girdi boru_oku() (pipe_read( )) fonksiyonuna işaret eder. A process wishing to get data from a pipe issues a read( ) system call, specifying as its file descriptor the descriptor associated with the pipe's read channel. The kernel ends up invoking the read method found in the file operation table associated with the proper file object. In the case of a pipe, the entry for the read method in the read_pipe_fops table points to the pipe_read( ) function.
boru_oku() (pipe_read( )) fonksiyonu çok ilişilidir, çünkü POSIX standardı borunun okuyuş işlemlerine bir çok şart koşmuştur. Tablo 18-2 boru uzunluğu p olan(okunacak boru arabölgesindeki byteların sayısı) bir borudan n byte rica eden, oku() (read( )) sistem çağrısının umulan davranışını gösterir. Okuyuş işleminin tıkanmasız(nonblocking) olabileceğine dikkat ediniz: bu durumda, var olan bütün bytelar kullanıcı adres boşluğuna[3] kopyalanır kopyalanmaz
tamamlanır. Ayrıca, yalnız eğer boru boş ise ve borunun yazıcı kanalı ile ilişkilendirilmiş dosya nesnesini o anda hiçbir süreç kullanmıyor ise oku() (read( )) sistem çağrısı tarafından değer döndürülür.
The pipe_read( ) function is quite involved, since the POSIX standard specifies several requirements for the pipe's read operations. Table 18-2 illustrates the expected behavior of a read( ) system call that requests n bytes from a pipe having a pipe size (number of bytes in the pipe buffer yet to be read) equal to p. Notice that the read operation can be nonblocking: in this case, it completes as soon as all available bytes (even none) have been copied into the user address space.[3] Notice also that the value is returned by the read( ) system call only if the pipe is empty and no process is currently using the file object associated with the pipe's write channel.
[3] Tıkanmasız işlemler genellikle aç() (open( )) sistem çağrısı içinde O_TIKANMASIZ (O_NONBLOCK) bayrağını belirleyerek talep edilir. Bu yöntem açılamadıkları için borulara geçerli değildir; bir süreç yine de karşı düşen dosya tanımlayıcı üzerinde bir dkntl() (fcntl( )) sistem çağrısı yaparak tıkanmasız bir işlem yapılmasını şart koşabilir.
[3] Nonblocking operations are usually requested by specifying the O_NONBLOCK flag in the open( ) system call. This method does not
work for pipes, since they cannot be opened; a process can, however, require a nonblocking operation on a pipe by issuing a fcntl( ) system
call on the corresponding file descriptor.
Tablo 18-2. Bir Borudan Byte’ların Okunuşu (Reading n Bytes from a Pipe)
Fonksiyon aşağıdaki işlemleri icra eder:
1. idüğüm(inode)'ün i_boy (i_size) alanına depolanmış olan boru boyunun 0 olup olmadığını belirler. Bu durumda, fonksiyonun geri dönüşünün zorunluluğunu veya başka bir süreç boruya yazı yazışını beklerken tıkanmasının zorunlu olup olmadığını belirler(Bakınız Tablo 18-2).
The function performs the following operations:
1. Determines if the pipe size, which is stored into the inode's i_size field, is 0. In this case, determines if the function must return or if the process must be blocked while waiting until another process writes some data in the pipe (see Table 18-2).
G/Ç işleminin türü (tıkanarak ya da tıkanmasız) olacağı dosya nesnesinin d_bayraklar (f_flags) alanının O_TIKANMASIZ (O_NONBLOCK) bayrağı tarafından belirlenir. Eğer gerekirse, o andaki süreci, boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının bekle(wait) alanının işaret ettiği bekleyiş kuyruğuna soktukup sonra da askıya almak için kesilebilir_bekle_durumunda() (interruptible_sleep_on()) fonksiyonunu başlatır.
The type of I/O operation (blocking or nonblocking) is specified by the O_NONBLOCK flag in the f_flags field of the file object. If necessary, invokes the interruptible_sleep_on() function to suspend the current process after having inserted it in the wait queue to
which the wait field of the pipe_inode_info data structure points.
2. boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının kilit (lock) alanını sınar. Eğer boş değil ise,
başka bir süreç o anda boruya erişmektedir; bu durumda, ya o anki süreci askıya alır ya da okuyuş işleminin tipine göre (tıkanmasız ya da tıkayıcılı) sistem çağrısını sona erdirir.
3. lock alanını arttırır.
4. Borunun arabölgesinden kullanıcı adres boşluğuna istenen sayıda (ya da elde var olan bytelar kadar olanı, eğer arabölge çok küçük ise) byte’ı kopyalar.
5. lock alanını azaltır.
6. Borunun bekleyiş kuyruğundaki bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
7. Kullanıcı adres boşluğuna kopyalanmış olan byte’ların sayısını geri döndürür.
2. Checks the lock field of the pipe_inode_info data structure. If it is not null, another process is currently accessing the pipe; in this case, either suspends the current process or immediately terminates the system call, depending on the type of read operation (blocking or nonblocking).
3. Increments the lock field.
4. Copies the requested number of bytes (or the number of available bytes, if the buffer size is too small) from the pipe's buffer to the user address space.
5. Decrements the lock field.
6. Invokes wake_up_interruptible( ) to wake up all processes sleeping on the pipe's wait queue.
7. Returns the number of bytes copied into the user address space.
18.1.5 Boruya yazış (Writing into a Pipe)
Bir boruya veri koymak dileyen bir süreç, kendi dosya tanımlayıcısı olarak borunun yazıcı kanalı ile ilişkili tanımlayıcıyı kendi dosya tanımlayıcısı olarak belirleyerek, bir yaz() (write( )) system çağrısı çıkarır. Çekirdek bu isteği uygun dosya nesnesinin yaz (write) yöntemini başlatarak tatmin eder; yaz_boru_dişl() (write_pipe_fops) tablosunda karşı düşen girdi boru_yaz() (pipe_write( )) fonksiyonuna işaret eder. Tablo 18-3, POSIX standardına göre, arabölgesinde u (unused) kullanılmamış byte’ı olan bir borunun içine n byte yazmak isteyen bir yaz (write( )) sistem çağrısının davranışını canlandırmaktadır.
A process wishing to put data into a pipe issues a write( ) system call, specifying as its file descriptor the descriptor associated with the pipe's write channel. The kernel satisfies this request by invoking the write method of the proper file object; the corresponding entry in the write_pipe_fops table points to the pipe_write( ) function. Table 18-3 illustrates the behavior, specified by the POSIX standard, of a write( ) system call that requested to write n bytes into a pipe having u unused bytes in its buffer.
Standart özellikle küçük sayıda bytela ilgili yazıcı işlemlerin otomatik olarak ifa edilişini zorunlu kılar. Daha doğrusu, eğer iki ya da daha çok süreç boruya eş zamanlı yazıyorsalar, 4096’dan daha az (boru arabölgesi boyu) byte ile ilgili herhangi bir yazıcı işlem aynı boruya başka süreçler tarafından yapılan yazıcı işlemler ile içiçe geçirilmeden(interleave) bitmek zorundadır. Yine de, 4096 byte’tan daha uzun yazıcı işlemler gayrı-atomik olabilirler ve çağırıcı sürecin uyutuluşunu zorunlu kılabilirler.
In particular, the standard requires that write operations involving a small number of bytes must be automatically executed.
More precisely, if two or more processes are concurrently writing into a pipe, any write operation involving fewer than 4096 bytes (the pipe buffer size) must finish without being interleaved with write operations of other processes to the same pipe.
However, write operations involving more than 4096 bytes may be nonatomic and may also force the calling process to sleep.
Table 18-3. Bir Boruya n tane byte’ın yazılışı
Dahası, eğer bir borunun okuyucu süreci yoksa (yani idüğüm nesnesinin readers alanı 0 değerine sahipse) o boruya yazıcı bütün işlemler başarısız olmalıdır. O durumda, çekirdek yazıcı sürece bir -EPIPE hata kodu ile, bir SIGPIPE işareti gönderir, bu ise tanıdık “Kırık Boru” mesajına yol açar.
Moreover, any write operation to a pipe must fail if the pipe does not have a reading process (that is, if the readers field of the pipe's inode object has the value 0). In that case, the kernel sends a SIGPIPE signal to the writing process and terminates the write( ) system call with the -EPIPE error code, which usually leads to the familiar "Broken pipe" message.
pipe_write( ) fonksiyonu aşağıdaki işlemleri icra eder:
1. Borunun en azından bir okuyucu süreci olduğunu sınar. Eğer değilse, şuanki (current) sürece BORUİŞA (SIGPIPE) işaretini gönderir ve bir -EBORU (-EPIPE) değerini geri döndürür.
2. Borunun idüğümünün (inode) sys_write( ) fonksiyonu tarafından ayrılmış, i_sem semaforunu serbest bırakır ve aynı düğümün the i_atomik_yaz() (i_atomic_write) semaforunu ayırır. [4]
The pipe_write( ) function performs the following operations:
1. Checks whether the pipe has at least one reading process. If not, sends a SIGPIPE signal to the current process and return an -EPIPE value.
2. Releases the i_sem semaphore of the pipe's inode, which was acquired by the sys_write( ) function, and acquires the i_atomic_write semaphore of the same node. [4]
[4] i_sem semaforu çok sayıda sürecin bir dosya üzerinde yazış işlemleri başlatışını önler, ve dolayısıyla boru üzerinde de.
[4] The i_sem semaphore prevents multiple processes from starting write operations on a file, and thus on the pipe
3. Yazılacak byteların sayısının borunun arabölge boyu içinde olup olmadığını kontrol eder:
a. Eğer öyle ise, yazış işlemi atomik olmak zorundadır. Dolayısıyla, arabölgenin yazılacak bütün byteları depolayabilecek yeterli serbest boşluğa sahip olduğunu kontrol eder.
b. Eğer byteların sayısı arabölge boyundan daha büyükse, bir parça serbest boşluk olduğu sürece işlem başlar. Dolayısıyla en azından 1 byte boş yer olduğunu sınar.
3. Checks whether the number of bytes to be written is within the pipe's buffer size:
a.If so, the write operation must be atomic. Therefore, checks whether the buffer has enough free space to store all bytes to be written.
b. If the number of bytes is greater than the buffer size, the operation can start as long as there is any free space at all. Therefore, checks for at least 1 free byte.
4. Eğer arabölge yeterli serbest boşluğa sahip değilse ve yazıcı işlem tıkayıcıysa, şu andaki süreci borunun bekleyiş kuyruğuna sokar ve borudan bir miktar veri okununcaya kadar onu askıya alır. i_atomik_yaz() (i_atomic_write) semaforun serbest bırakılmadığının farkına varınız, dolayısıyla başka hiçbir süreç boru üstünde yazıcı bir işlem başlatamaz. Eğer yazıcı işlem tıkanmasız ise, -ETEKRAR (-EAGAIN) hata kodunu geri döndürür.
4. If the buffer does not have enough free space and the write operation is blocking, inserts the current process into the pipe's wait queue and suspends it until some data is read from the pipe. Notice that the i_atomic_write semaphore is not released, so no other process can start a write operation on the buffer. If the write operation is nonblocking, returns the -EAGAIN error code.
5. pipe_inode_info veri yapısının lock alanını sınar. Eğer boş değilse, bir başka süreç o anda boruyu okuyordur, dolayısıyla ya o anki süreci askıya alır ya da yazış işleminin tıkayıcı veya tımasız oluşuna bağlı olarak yazışı hemen sona erdirir.
6. kilit (lock) alanını arttırır.
7. İstenen sayıda byte’i (eğer boru boyu çok kısa ise serbest byte sayısı kadarını) kullanıcı adres boşluğundan borunun arabölgesine taşır.
8. Eğer hala yazılışı gereken bytelar var ise 4. adıma gider.
9. İstenen bütün veri yazıldıktan sonra, kilit (lock) alanını azaltır.
10. Borunun bekleyiş kuyruğunda bekleyen bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
11. i_atomic_write semaforu serbest bırakır ve i_sem semaforunu bağlar (böylece sys_write( ) ikincisini kolaylıkla serbest bırakabilir).
12. Borunun arabölgesine yazılan byteların sayısını geri döndürür.
5. Checks the lock field of the pipe_inode_info data structure. If it is not null, another process is currently reading the pipe, so either suspends the current process or immediately terminates the write depending on whether the write operation is blocking or nonblocking.
6. Increments the lock field.
7. Copies the requested number of bytes (or the number of free bytes if the pipe size is too small) from the user address space to the pipe's buffer.
8. If there are bytes yet to be written, goes to step 4.
9. After all requested data is written, decrements the lock field.
10. Invokes wake_up_interruptible( ) to wake up all processes sleeping on the pipe's wait queue.
11. Releases the i_atomic_write semaphore and acquires the i_sem semaphore (so that sys_write( ) can safely release the latter).
12. Returns the number of bytes written into the pipe's buffer.
LINUX Çekirdeğini Anlamak – Süreçler Arası İletişim 4
Ali Rıza SARAL(1)
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1.4 Bir Borudan Okuyuş (Reading from a Pipe)
Bir borudan veri almak isteyen bir süreç, kendi dosya tanımlayıcısı olarak borunun okuyucu kanalı ile ilişkilendirilmiş tanımlayıcıyı belirleyerek bir oku() (read( )) sistem çağrısı çıkarır. Sonuç olarak, çekirdek, dosya işlem tablosunda uygun bir dosya nesnesi ile ilişkilendirilmiş bir oku (read) metodunu başlatır. Bir boru durumunda, oku (read) metodu için oku_boru_dişl (read_pipe_fops) tablosundaki bir girdi boru_oku() (pipe_read( )) fonksiyonuna işaret eder. boru_oku() (pipe_read( )) fonksiyonu çok ilişkilidir, çünkü POSIX standardı borunun okuyuş işlemlerine bir çok şart koşmuştur. Tablo 18-2 boru uzunluğu p olan(okunacak boru arabölgesindeki byteların sayısı) bir borudan n byte rica eden, oku() (read( )) sistem çağrısının umulan davranışını gösterir. Okuyuş işleminin tıkanmasız(nonblocking) olabileceğine dikkat ediniz: bu durumda işlem, var olan bütün bytelar kullanıcı adres boşluğuna[3] kopyalanır kopyalanmaz tamamlanır. Ayrıca, yalnız eğer boru boş ise ve borunun yazıcı kanalı ile ilişkilendirilmiş dosya nesnesini o anda hiçbir süreç kullanmıyor ise oku() (read( )) sistem çağrısı tarafından değer döndürülür.
[3] Tıkanmasız işlemler genellikle aç() (open( )) sistem çağrısı içinde O_TIKANMASIZ (O_NONBLOCK) bayrağını belirleyerek talep edilir. Bu yöntem açılamadıkları için borulara geçerli değildir; bir süreç yine de karşı düşen dosya tanımlayıcı üzerinde bir dkntl() (fcntl( )) sistem çağrısı yaparak tıkanmasız bir işlem yapılmasını şart koşabilir.
Tablo 18-2. Bir Borudan Byte’ların Okunuşu (Reading n Bytes from a Pipe)
Fonksiyon aşağıdaki işlemleri icra eder:
1. idüğüm(inode)'ün i_boy (i_size) alanına depolanmış olan boru boyunun 0 olup olmadığını belirler. Bu durumda, fonksiyonun geri dönüşünün zorunluluğunu veya başka bir süreç boruya yazı yazışını beklerken tıkanmasının zorunlu olup olmadığını belirler(Bakınız Tablo 18-2). G/Ç işleminin türü (tıkanarak ya da tıkanmasız) olacağı dosya nesnesinin d_bayraklar (f_flags) alanının O_TIKANMASIZ (O_NONBLOCK) bayrağı tarafından belirlenir. Eğer gerekirse, o andaki süreci, boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının bekle(wait) alanının işaret ettiği bekleyiş kuyruğuna sokturup sonra da askıya almak için kesilebilir_bekle_durumunda() (interruptible_sleep_on()) fonksiyonunu başlatır.
2. boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının kilit (lock) alanını sınar. Eğer boş değil ise,
başka bir süreç o anda boruya erişmektedir; bu durumda, ya o anki süreci askıya alır ya da okuyuş işleminin tipine göre (tıkanmasız ya da tıkayıcılı) sistem çağrısını sona erdirir.
3. lock alanını arttırır.
4. Borunun arabölgesinden kullanıcı adres boşluğuna istenen sayıda (ya da elde var olan bytelar kadar olanı, eğer arabölge çok küçük ise) byte’ı kopyalar.
5. lock alanını azaltır.
6. Borunun bekleyiş kuyruğundaki bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
7. Kullanıcı adres boşluğuna kopyalanmış olan byte’ların sayısını geri döndürür.
18.1.5 Boruya yazış (Writing into a Pipe)
Bir boruya veri koymak dileyen bir süreç, kendi dosya tanımlayıcısı olarak borunun yazıcı kanalı ile ilişkili tanımlayıcıyı kendi dosya tanımlayıcısı olarak belirleyerek, bir yaz() (write( )) system çağrısı çıkarır. Çekirdek bu isteği uygun dosya nesnesinin yaz (write) yöntemini başlatarak tatmin eder; yaz_boru_dişl() (write_pipe_fops) tablosunda karşı düşen girdi boru_yaz() (pipe_write( )) fonksiyonuna işaret eder. Tablo 18-3, POSIX standardına göre, arabölgesinde u (unused) kullanılmamış byte’ı olan bir borunun içine n byte yazmak isteyen bir yaz (write( )) sistem çağrısının davranışını canlandırmaktadır. Standart özellikle küçük sayıda bytela ilgili yazıcı işlemlerin otomatik olarak ifa edilişini zorunlu kılar. Daha doğrusu, eğer iki ya da daha çok süreç boruya eş zamanlı yazıyorsalar, 4096’dan daha az (boru arabölgesi boyu) byte ile ilgili herhangi bir yazıcı işlem aynı boruya başka süreçler tarafından yapılan yazıcı işlemler ile içiçe geçirilmeden(interleave) bitmek zorundadır. Yine de, 4096 byte’tan daha uzun yazıcı işlemler gayrı-atomik olabilirler ve çağırıcı sürecin uyutuluşunu zorunlu kılabilirler.
Table 18-3. Bir Boruya n tane byte’ın yazılışı
Dahası, eğer bir borunun okuyucu süreci yoksa (yani idüğüm nesnesinin readers alanı 0 değerine sahipse) o boruya yazıcı bütün işlemler başarısız olmalıdır. O durumda, çekirdek yazıcı sürece bir -EPIPE hata kodu ile, bir SIGPIPE işareti gönderir, bu ise tanıdık “Kırık Boru” mesajına yol açar. pipe_write( ) fonksiyonu aşağıdaki işlemleri icra eder:
1. Borunun en azından bir okuyucu süreci olduğunu sınar. Eğer değilse, şuanki (current) sürece BORUİŞA (SIGPIPE) işaretini gönderir ve bir -EBORU (-EPIPE) değerini geri döndürür.
2. Borunun idüğümünün (inode) sys_write( ) fonksiyonu tarafından ayrılmış, i_sem semaforunu serbest bırakır ve aynı düğümün the i_atomik_yaz() (i_atomic_write) semaforunu ayırır. [4]
[4] i_sem semaforu çok sayıda sürecin bir dosya üzerinde yazış işlemleri başlatışını önler, ve dolayısıyla boru üzerinde de.
3. Yazılacak byteların sayısının borunun arabölge boyu içinde olup olmadığını kontrol eder:
a. Eğer öyle ise, yazış işlemi atomik olmak zorundadır. Dolayısıyla, arabölgenin yazılacak bütün byteları depolayabilecek yeterli serbest boşluğa sahip olduğunu kontrol eder.
b. Eğer byteların sayısı arabölge boyundan daha büyükse, bir parça serbest boşluk olduğu sürece işlem başlar. Dolayısıyla en azından 1 byte boş yer olduğunu sınar.
4. Eğer arabölge yeterli serbest boşluğa sahip değilse ve yazıcı işlem tıkayıcıysa, şu andaki süreci borunun bekleyiş kuyruğuna sokar ve borudan bir miktar veri okununcaya kadar onu askıya alır. i_atomik_yaz() (i_atomic_write) semaforun serbest bırakılmadığının farkına varınız, dolayısıyla başka hiçbir süreç boru üstünde yazıcı bir işlem başlatamaz. Eğer yazıcı işlem tıkanmasız ise, -ETEKRAR (-EAGAIN) hata kodunu geri döndürür.
5. pipe_inode_info veri yapısının lock alanını sınar. Eğer boş değilse, bir başka süreç o anda boruyu okuyordur, dolayısıyla ya o anki süreci askıya alır ya da yazış işleminin tıkayıcı veya tımasız oluşuna bağlı olarak yazışı hemen sona erdirir.
6. kilit (lock) alanını arttırır.
7. İstenen sayıda byte’i (eğer boru boyu çok kısa ise serbest byte sayısı kadarını) kullanıcı adres boşluğundan borunun arabölgesine taşır.
8. Eğer hala yazılışı gereken bytelar var ise 4. adıma gider.
9. İstenen bütün veri yazıldıktan sonra, kilit (lock) alanını azaltır.
10. Borunun bekleyiş kuyruğunda bekleyen bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
11. i_atomic_write semaforu serbest bırakır ve i_sem semaforunu bağlar (böylece sys_write( ) ikincisini kolaylıkla serbest bırakabilir).
12. Borunun arabölgesine yazılan byteların sayısını geri döndürür.
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1.4 Bir Borudan Okuyuş (Reading from a Pipe)
Bir borudan veri almak isteyen bir süreç, kendi dosya tanımlayıcısı olarak borunun okuyucu kanalı ile ilişkilendirilmiş tanımlayıcıyı belirleyerek bir oku() (read( )) sistem çağrısı çıkarır. Sonuç olarak, çekirdek, dosya işlem tablosunda uygun bir dosya nesnesi ile ilişkilendirilmiş bir oku (read) metodunu başlatır. Bir boru durumunda, oku (read) metodu için oku_boru_dişl (read_pipe_fops) tablosundaki bir girdi boru_oku() (pipe_read( )) fonksiyonuna işaret eder. boru_oku() (pipe_read( )) fonksiyonu çok ilişkilidir, çünkü POSIX standardı borunun okuyuş işlemlerine bir çok şart koşmuştur. Tablo 18-2 boru uzunluğu p olan(okunacak boru arabölgesindeki byteların sayısı) bir borudan n byte rica eden, oku() (read( )) sistem çağrısının umulan davranışını gösterir. Okuyuş işleminin tıkanmasız(nonblocking) olabileceğine dikkat ediniz: bu durumda işlem, var olan bütün bytelar kullanıcı adres boşluğuna[3] kopyalanır kopyalanmaz tamamlanır. Ayrıca, yalnız eğer boru boş ise ve borunun yazıcı kanalı ile ilişkilendirilmiş dosya nesnesini o anda hiçbir süreç kullanmıyor ise oku() (read( )) sistem çağrısı tarafından değer döndürülür.
[3] Tıkanmasız işlemler genellikle aç() (open( )) sistem çağrısı içinde O_TIKANMASIZ (O_NONBLOCK) bayrağını belirleyerek talep edilir. Bu yöntem açılamadıkları için borulara geçerli değildir; bir süreç yine de karşı düşen dosya tanımlayıcı üzerinde bir dkntl() (fcntl( )) sistem çağrısı yaparak tıkanmasız bir işlem yapılmasını şart koşabilir.
Tablo 18-2. Bir Borudan Byte’ların Okunuşu (Reading n Bytes from a Pipe)
Fonksiyon aşağıdaki işlemleri icra eder:
1. idüğüm(inode)'ün i_boy (i_size) alanına depolanmış olan boru boyunun 0 olup olmadığını belirler. Bu durumda, fonksiyonun geri dönüşünün zorunluluğunu veya başka bir süreç boruya yazı yazışını beklerken tıkanmasının zorunlu olup olmadığını belirler(Bakınız Tablo 18-2). G/Ç işleminin türü (tıkanarak ya da tıkanmasız) olacağı dosya nesnesinin d_bayraklar (f_flags) alanının O_TIKANMASIZ (O_NONBLOCK) bayrağı tarafından belirlenir. Eğer gerekirse, o andaki süreci, boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının bekle(wait) alanının işaret ettiği bekleyiş kuyruğuna sokturup sonra da askıya almak için kesilebilir_bekle_durumunda() (interruptible_sleep_on()) fonksiyonunu başlatır.
2. boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının kilit (lock) alanını sınar. Eğer boş değil ise,
başka bir süreç o anda boruya erişmektedir; bu durumda, ya o anki süreci askıya alır ya da okuyuş işleminin tipine göre (tıkanmasız ya da tıkayıcılı) sistem çağrısını sona erdirir.
3. lock alanını arttırır.
4. Borunun arabölgesinden kullanıcı adres boşluğuna istenen sayıda (ya da elde var olan bytelar kadar olanı, eğer arabölge çok küçük ise) byte’ı kopyalar.
5. lock alanını azaltır.
6. Borunun bekleyiş kuyruğundaki bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
7. Kullanıcı adres boşluğuna kopyalanmış olan byte’ların sayısını geri döndürür.
18.1.5 Boruya yazış (Writing into a Pipe)
Bir boruya veri koymak dileyen bir süreç, kendi dosya tanımlayıcısı olarak borunun yazıcı kanalı ile ilişkili tanımlayıcıyı kendi dosya tanımlayıcısı olarak belirleyerek, bir yaz() (write( )) system çağrısı çıkarır. Çekirdek bu isteği uygun dosya nesnesinin yaz (write) yöntemini başlatarak tatmin eder; yaz_boru_dişl() (write_pipe_fops) tablosunda karşı düşen girdi boru_yaz() (pipe_write( )) fonksiyonuna işaret eder. Tablo 18-3, POSIX standardına göre, arabölgesinde u (unused) kullanılmamış byte’ı olan bir borunun içine n byte yazmak isteyen bir yaz (write( )) sistem çağrısının davranışını canlandırmaktadır. Standart özellikle küçük sayıda bytela ilgili yazıcı işlemlerin otomatik olarak ifa edilişini zorunlu kılar. Daha doğrusu, eğer iki ya da daha çok süreç boruya eş zamanlı yazıyorsalar, 4096’dan daha az (boru arabölgesi boyu) byte ile ilgili herhangi bir yazıcı işlem aynı boruya başka süreçler tarafından yapılan yazıcı işlemler ile içiçe geçirilmeden(interleave) bitmek zorundadır. Yine de, 4096 byte’tan daha uzun yazıcı işlemler gayrı-atomik olabilirler ve çağırıcı sürecin uyutuluşunu zorunlu kılabilirler.
Table 18-3. Bir Boruya n tane byte’ın yazılışı
Dahası, eğer bir borunun okuyucu süreci yoksa (yani idüğüm nesnesinin readers alanı 0 değerine sahipse) o boruya yazıcı bütün işlemler başarısız olmalıdır. O durumda, çekirdek yazıcı sürece bir -EPIPE hata kodu ile, bir SIGPIPE işareti gönderir, bu ise tanıdık “Kırık Boru” mesajına yol açar. pipe_write( ) fonksiyonu aşağıdaki işlemleri icra eder:
1. Borunun en azından bir okuyucu süreci olduğunu sınar. Eğer değilse, şuanki (current) sürece BORUİŞA (SIGPIPE) işaretini gönderir ve bir -EBORU (-EPIPE) değerini geri döndürür.
2. Borunun idüğümünün (inode) sys_write( ) fonksiyonu tarafından ayrılmış, i_sem semaforunu serbest bırakır ve aynı düğümün the i_atomik_yaz() (i_atomic_write) semaforunu ayırır. [4]
[4] i_sem semaforu çok sayıda sürecin bir dosya üzerinde yazış işlemleri başlatışını önler, ve dolayısıyla boru üzerinde de.
3. Yazılacak byteların sayısının borunun arabölge boyu içinde olup olmadığını kontrol eder:
a. Eğer öyle ise, yazış işlemi atomik olmak zorundadır. Dolayısıyla, arabölgenin yazılacak bütün byteları depolayabilecek yeterli serbest boşluğa sahip olduğunu kontrol eder.
b. Eğer byteların sayısı arabölge boyundan daha büyükse, bir parça serbest boşluk olduğu sürece işlem başlar. Dolayısıyla en azından 1 byte boş yer olduğunu sınar.
4. Eğer arabölge yeterli serbest boşluğa sahip değilse ve yazıcı işlem tıkayıcıysa, şu andaki süreci borunun bekleyiş kuyruğuna sokar ve borudan bir miktar veri okununcaya kadar onu askıya alır. i_atomik_yaz() (i_atomic_write) semaforun serbest bırakılmadığının farkına varınız, dolayısıyla başka hiçbir süreç boru üstünde yazıcı bir işlem başlatamaz. Eğer yazıcı işlem tıkanmasız ise, -ETEKRAR (-EAGAIN) hata kodunu geri döndürür.
5. pipe_inode_info veri yapısının lock alanını sınar. Eğer boş değilse, bir başka süreç o anda boruyu okuyordur, dolayısıyla ya o anki süreci askıya alır ya da yazış işleminin tıkayıcı veya tımasız oluşuna bağlı olarak yazışı hemen sona erdirir.
6. kilit (lock) alanını arttırır.
7. İstenen sayıda byte’i (eğer boru boyu çok kısa ise serbest byte sayısı kadarını) kullanıcı adres boşluğundan borunun arabölgesine taşır.
8. Eğer hala yazılışı gereken bytelar var ise 4. adıma gider.
9. İstenen bütün veri yazıldıktan sonra, kilit (lock) alanını azaltır.
10. Borunun bekleyiş kuyruğunda bekleyen bütün süreçleri uyandırmak için uyandır_kesilebiliri() (wake_up_interruptible( )) ‘ı başlatır.
11. i_atomic_write semaforu serbest bırakır ve i_sem semaforunu bağlar (böylece sys_write( ) ikincisini kolaylıkla serbest bırakabilir).
12. Borunun arabölgesine yazılan byteların sayısını geri döndürür.
Saturday 26 January 2008
LINUX Çekirdeğini Anlamak – Süreçler Arası İletişim 3
Ali Rıza SARAL(1)
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1.2 Boru Veri Yapıları (Pipe Data Structures)
Şimdi tekrar sistem çağrısı seviyesinde düşünmeğe başlamalıyız. Bir kere bir boru yaratıldı mı, bir süreç oku() (read( ) ve yaz() (write( )) Sanal Dosya sistemi (VFS) çağrılarını kullanarak ona erişir. Bu yüzden her boru için, çekirdek biri okumak diğeri yazmak için iki tane dosya nesnesi ve bir idüğüm (inode) nesnesi yaratır. Bir süreç bir boruya yazmağa veya onu okumağa başladığında uygun dosya tanımlayıcıyı kullanmalıdır.
Bir idüğüm (inode) nesnesi bir boruya değindiğinde, kendisinin u alanı bir boru_idüğüm_bilgi (pipe_inode_info yapısı)’ndan oluşur, Table 18-1’de görüldüğü gibi.
 Tablo 18-1. boru_idüğüm_bilgi yapısı (The pipe_inode_info Structure)
Tablo 18-1. boru_idüğüm_bilgi yapısı (The pipe_inode_info Structure)
Tip Alan Tanım
char * base Address of kernel buffer
unsigned int start Read position in kernel buffer
unsigned int lock Locking flag for exclusive access
struct wait_queue * wait Pipe/FIFO wait queue
unsigned int readers Flag for (or number of) reading processes
unsigned int writers Flag for (or number of) writing processes
unsigned int rd_openers Used while opening a FIFO for reading
unsigned int wr_openers Used while opening a FIFO for writing
Bir idüğüm ve iki dosya nesnesi dışında, her boru kendi boru arabölgesine (pipe buffer) ‘una sahiptir, yani boruya yazılmış ve hala okunuşu gereken tek bir sayfa çerçevesi (page frame). Bu sayfa çerçevesinin adresi boru_idüğüm_bilgi (pipe_inode_info) yapısının zemin (base) alanına depolanır. idüğüm (inode) nesnesinin i_büyüklük (i_size) alanı henüz okunuşu gerçekleşmemiş boru arabölgesine (buffer) yazılmış byte’ların sayısını depolar; aşağıda o sayıya şu andaki boru büyüklüğü (pipe size) diyoruz.
Boru arabölgesine hem yazan hem de okuyan süreçler tarafından erişilir, bu yüzden çekirdek arabölge içinde iki şuandaki konumun izini takip etmek zorundadır:
• boru_idüğüm_bilgisi (pipe_inode_info) yapısının başla (start) alanı içine depolanan okunacak ilk byte’ın göreli konumu
• başla (start) ve boru Büyüklüğü’nden çıkartılan yazılacak ilk byteın göreli konumu
Boru’nun veri yapıları üzerinde yarışım koşullarından sakınmak için, çekirdek bore arabölgesine eşzamanlı (concurrent) erişimleri yasaklar. Bunu başarmak için, boru_idüğüm_bilgisi (pipe_inode_info veri yapısındaki kilit (lock) alanından faydalanır. Maalesef, kilit (lock) alanı yeterli değildir. Göreceğimiz gibi, POSIX bazı boru işlemlerinin atomik lmasını zorunlu kılar. Dahası, POSIX okuyucuların arabölgeyi boşaltabilmeleri için, boru dolu olduğu zaman yazıcı süreçin askıya alınışına müsaade eder. Bu şartlar, idüğüm nesnesi içinde bulunan ek bir i_atomik_yaz (i_atomic_write) semaforunu kullanarak sağlanır: bu semafor bir başka yazıcı arabölge dolu olduğundan askıya alınmışken bir sürecin yeni bir yazıcı işlem başlatışını engeller.
18.1.3 Bir Boru Yaratmak ve Yok Etmek (Creating and Destroying a Pipe)
Bir boru disk görüntüsü olmayan bir küme SanalDosyaSistemi (VFS) nesnesi olarak gerçekleştirilir. Aşağıdaki tartışmada göreceğimiz gibi, bir boru, en azından bir süreç ona değinen bir dosya tanımlayıcıya sahip olduğu sürece, sistem içinde kalır.
boru() (pipe( )) sistem çağrısına, boru_yap() (do_pipe( )) fonksiyonunu çağıran sis_boru() (sys_pipe( )) fonksiyonu tarafından hizmet edilir. Yeni bir boru yaratmak için, boru_yap() aşağıdaki işlemleri yapar:
1. Borunun okuyucu kanalı için bir dosya nesnesi ve dosya tanımlayıcı ayırır, dosya nesnesinin bayrak (flag) alanını O_YALNIZOKU (O_RDONLY) ’ya ayarlar, ve d_işle (f_op) alanını the roku_boru_dişlem (read_ pipe_fops) tablosunun adresi ile başlangıç-koşullar.
2. Borunun yazıcı kanalı için bir dosya nesnesi ve dosya tanımlayıcı ayırır, dosya nesnesinin bayrak (flag) alanını O_YALNIZYAZ (O_WRONLY) ’ya ayarlar, ve d_işle (f_op) alanını the roku_boru_dişlem (write_ pipe_fops) tablosunun adresi ile başlangıç-koşullar.
3. Boru için bir idüğüm (inode) nesnesini başlangıç koşullayan boru_idüğümünü_edin (get_ pipe_inode( )) fonksiyonunu başlatır. Bu fonksiyon boru arabölgesi için aynı zamanda bir sayfa çerçevesi ayırır ve onun adresini pipe_inode_info yapısının base alanına depolar.
4. dentry nesnesini ayırır ve onu iki dosya nesnesini ve idüğüm (inode) nesnesini birbirine ilişkilendirmek için kullanır.
5. Kullanıcı Üslubundaki sürece iki dosya tanımlayıcıyı geri döndürür.
Yeni bir boruya yazmak veya okumak için erişebilen tek süreç bir boru() (pipe( )) sistem
çağrısı çıkartan süreçtir. Borunun bir okuyucu ve bir yazıcıya gerçekten sahip olduğunu temsil etmek için boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının okuyucular (readers) ve yazıcılar (writers) alanları 1 başlangıç değerlerini alır. Genel olarak, eğer karşı düşen borunun dosya nesnesi hala açık ise bu her iki alana 1 değeri verilir; Eğer karşı düşen dosya nesnesi serbest bırakılmışsa bu alana 0 değeri verilir, çünkü artık başka hiçbir süreçtarafından erişilmez. Yeni bir süreci çatallamak (forking) okuyucular (readers) ve yazıcılar (writers) alanlarının değerlerini arttırmaz, dolayısıyla değerleri hiçbir zaman 1 ‘in üstüne çıkmaz; yine de hala ebeveyn süreç tarafından kullanılan bütün dosya nesnelerinin kullanım sayaçlarının değerlerini arttırır. Böylece, ebeveyn ölse bile nesneler serbest bırakılmaz, ve boru çocukların kullanışı için açık kalacaktır. FIFO’larla ilişkilendirildiklerinde okuyucular (readers) ve yazıcılar (writers) alanları bayrak yerine sayaç olarak kullanılırlar.
Ne zaman bir süreç, bir boru ile alakalı bir dosya tanımlayıcı üzerinde bir kapa() (close( )) sistem çağrısı başlatırsa, çekirdek kullanım sayacını azaltan dkoy() fput( ) fonksiyonunu karşı düşen nesne üzerinde çalıştırır. Eğer sayaç 0 olursa, fonksiyon dosya işlemlerinin serbestbırak (release) metodunu çalıştırır.
Boru_okuyuş_sal() (pipe_read_release( )) ve boru_yazış_sal() (pipe_write_release( )) fonksiyonlarının her ikisi de borunun dosya nesnelerinin serbestbırak (release) metodlarını gerçekleştirilişi için kullanılırlar. boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının okuyucular (readers) ve yazıcılar (writers) alanlarına değer verirler. Daha sonra her fonksiyon boru_serbestbirak() (pipe_release( )) fonksiyonunu başlatır. Bu fonksiyon borunun durumundaki değişiklikten farkına varışları için borunun bekleyiş kuyruğundaki herbir süreci uyandırır. Dahası, fonksiyon okuyucular (readers) ve yazıcılar (writers) alanlarının 0 olup olmadıklarını sınar; eğer böyle ise, boru arabölgesini içeren sayfa çerçevesini serbest bırakır.
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1.2 Boru Veri Yapıları (Pipe Data Structures)
Şimdi tekrar sistem çağrısı seviyesinde düşünmeğe başlamalıyız. Bir kere bir boru yaratıldı mı, bir süreç oku() (read( ) ve yaz() (write( )) Sanal Dosya sistemi (VFS) çağrılarını kullanarak ona erişir. Bu yüzden her boru için, çekirdek biri okumak diğeri yazmak için iki tane dosya nesnesi ve bir idüğüm (inode) nesnesi yaratır. Bir süreç bir boruya yazmağa veya onu okumağa başladığında uygun dosya tanımlayıcıyı kullanmalıdır.
Bir idüğüm (inode) nesnesi bir boruya değindiğinde, kendisinin u alanı bir boru_idüğüm_bilgi (pipe_inode_info yapısı)’ndan oluşur, Table 18-1’de görüldüğü gibi.
 Tablo 18-1. boru_idüğüm_bilgi yapısı (The pipe_inode_info Structure)
Tablo 18-1. boru_idüğüm_bilgi yapısı (The pipe_inode_info Structure)Tip Alan Tanım
char * base Address of kernel buffer
unsigned int start Read position in kernel buffer
unsigned int lock Locking flag for exclusive access
struct wait_queue * wait Pipe/FIFO wait queue
unsigned int readers Flag for (or number of) reading processes
unsigned int writers Flag for (or number of) writing processes
unsigned int rd_openers Used while opening a FIFO for reading
unsigned int wr_openers Used while opening a FIFO for writing
Bir idüğüm ve iki dosya nesnesi dışında, her boru kendi boru arabölgesine (pipe buffer) ‘una sahiptir, yani boruya yazılmış ve hala okunuşu gereken tek bir sayfa çerçevesi (page frame). Bu sayfa çerçevesinin adresi boru_idüğüm_bilgi (pipe_inode_info) yapısının zemin (base) alanına depolanır. idüğüm (inode) nesnesinin i_büyüklük (i_size) alanı henüz okunuşu gerçekleşmemiş boru arabölgesine (buffer) yazılmış byte’ların sayısını depolar; aşağıda o sayıya şu andaki boru büyüklüğü (pipe size) diyoruz.
Boru arabölgesine hem yazan hem de okuyan süreçler tarafından erişilir, bu yüzden çekirdek arabölge içinde iki şuandaki konumun izini takip etmek zorundadır:
• boru_idüğüm_bilgisi (pipe_inode_info) yapısının başla (start) alanı içine depolanan okunacak ilk byte’ın göreli konumu
• başla (start) ve boru Büyüklüğü’nden çıkartılan yazılacak ilk byteın göreli konumu
Boru’nun veri yapıları üzerinde yarışım koşullarından sakınmak için, çekirdek bore arabölgesine eşzamanlı (concurrent) erişimleri yasaklar. Bunu başarmak için, boru_idüğüm_bilgisi (pipe_inode_info veri yapısındaki kilit (lock) alanından faydalanır. Maalesef, kilit (lock) alanı yeterli değildir. Göreceğimiz gibi, POSIX bazı boru işlemlerinin atomik lmasını zorunlu kılar. Dahası, POSIX okuyucuların arabölgeyi boşaltabilmeleri için, boru dolu olduğu zaman yazıcı süreçin askıya alınışına müsaade eder. Bu şartlar, idüğüm nesnesi içinde bulunan ek bir i_atomik_yaz (i_atomic_write) semaforunu kullanarak sağlanır: bu semafor bir başka yazıcı arabölge dolu olduğundan askıya alınmışken bir sürecin yeni bir yazıcı işlem başlatışını engeller.
18.1.3 Bir Boru Yaratmak ve Yok Etmek (Creating and Destroying a Pipe)
Bir boru disk görüntüsü olmayan bir küme SanalDosyaSistemi (VFS) nesnesi olarak gerçekleştirilir. Aşağıdaki tartışmada göreceğimiz gibi, bir boru, en azından bir süreç ona değinen bir dosya tanımlayıcıya sahip olduğu sürece, sistem içinde kalır.
boru() (pipe( )) sistem çağrısına, boru_yap() (do_pipe( )) fonksiyonunu çağıran sis_boru() (sys_pipe( )) fonksiyonu tarafından hizmet edilir. Yeni bir boru yaratmak için, boru_yap() aşağıdaki işlemleri yapar:
1. Borunun okuyucu kanalı için bir dosya nesnesi ve dosya tanımlayıcı ayırır, dosya nesnesinin bayrak (flag) alanını O_YALNIZOKU (O_RDONLY) ’ya ayarlar, ve d_işle (f_op) alanını the roku_boru_dişlem (read_ pipe_fops) tablosunun adresi ile başlangıç-koşullar.
2. Borunun yazıcı kanalı için bir dosya nesnesi ve dosya tanımlayıcı ayırır, dosya nesnesinin bayrak (flag) alanını O_YALNIZYAZ (O_WRONLY) ’ya ayarlar, ve d_işle (f_op) alanını the roku_boru_dişlem (write_ pipe_fops) tablosunun adresi ile başlangıç-koşullar.
3. Boru için bir idüğüm (inode) nesnesini başlangıç koşullayan boru_idüğümünü_edin (get_ pipe_inode( )) fonksiyonunu başlatır. Bu fonksiyon boru arabölgesi için aynı zamanda bir sayfa çerçevesi ayırır ve onun adresini pipe_inode_info yapısının base alanına depolar.
4. dentry nesnesini ayırır ve onu iki dosya nesnesini ve idüğüm (inode) nesnesini birbirine ilişkilendirmek için kullanır.
5. Kullanıcı Üslubundaki sürece iki dosya tanımlayıcıyı geri döndürür.
Yeni bir boruya yazmak veya okumak için erişebilen tek süreç bir boru() (pipe( )) sistem
çağrısı çıkartan süreçtir. Borunun bir okuyucu ve bir yazıcıya gerçekten sahip olduğunu temsil etmek için boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının okuyucular (readers) ve yazıcılar (writers) alanları 1 başlangıç değerlerini alır. Genel olarak, eğer karşı düşen borunun dosya nesnesi hala açık ise bu her iki alana 1 değeri verilir; Eğer karşı düşen dosya nesnesi serbest bırakılmışsa bu alana 0 değeri verilir, çünkü artık başka hiçbir süreçtarafından erişilmez. Yeni bir süreci çatallamak (forking) okuyucular (readers) ve yazıcılar (writers) alanlarının değerlerini arttırmaz, dolayısıyla değerleri hiçbir zaman 1 ‘in üstüne çıkmaz; yine de hala ebeveyn süreç tarafından kullanılan bütün dosya nesnelerinin kullanım sayaçlarının değerlerini arttırır. Böylece, ebeveyn ölse bile nesneler serbest bırakılmaz, ve boru çocukların kullanışı için açık kalacaktır. FIFO’larla ilişkilendirildiklerinde okuyucular (readers) ve yazıcılar (writers) alanları bayrak yerine sayaç olarak kullanılırlar.
Ne zaman bir süreç, bir boru ile alakalı bir dosya tanımlayıcı üzerinde bir kapa() (close( )) sistem çağrısı başlatırsa, çekirdek kullanım sayacını azaltan dkoy() fput( ) fonksiyonunu karşı düşen nesne üzerinde çalıştırır. Eğer sayaç 0 olursa, fonksiyon dosya işlemlerinin serbestbırak (release) metodunu çalıştırır.
Boru_okuyuş_sal() (pipe_read_release( )) ve boru_yazış_sal() (pipe_write_release( )) fonksiyonlarının her ikisi de borunun dosya nesnelerinin serbestbırak (release) metodlarını gerçekleştirilişi için kullanılırlar. boru_idüğüm_bilgisi (pipe_inode_info) veri yapısının okuyucular (readers) ve yazıcılar (writers) alanlarına değer verirler. Daha sonra her fonksiyon boru_serbestbirak() (pipe_release( )) fonksiyonunu başlatır. Bu fonksiyon borunun durumundaki değişiklikten farkına varışları için borunun bekleyiş kuyruğundaki herbir süreci uyandırır. Dahası, fonksiyon okuyucular (readers) ve yazıcılar (writers) alanlarının 0 olup olmadıklarını sınar; eğer böyle ise, boru arabölgesini içeren sayfa çerçevesini serbest bırakır.
Tuesday 15 January 2008
LINUX Çekirdeğini Anlamak – Süreçler Arası İletişim 2
Ali Rıza SARAL(1)
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1 Borular (Pipes)
Borular Unix’in bütün tat-türlerinde (flavor) bulunan bir süreçler arası iletişim mekanizmasıdır. Bir boru süreçler arasında tek yönlü veri akışıdır: bir süreç tarafından boruya yazılan verinin tamamı onu okuyan başka bir sürece çekirdek tarafından yönlendirilir.
Unix komut kabuklarında, borular operatörü ile yaratılır. Örneğin, aşağıdaki ifade kabuğa bir boru ile bağlı iki süreç yaratmağı emreder:
$ ls more
ls programını çalıştıran, birinci sürecin standart çıkışı boruya yönlendirilir; more programını çalıştıran ikinci süreç girdisini borudan okur. Aynı sonuçların iki ayrı komutu çalıştırarak elde edilebileceğini aklınızda tutunuz:
$ ls > temp
$ more < temp
İlk komut ls’in çıktısını alışılagelmiş bir dosyaya yöneltir; daha sonra ikinci komut more ‘u girişini aynı dosyadan okumağa zorlar. Tabii ki, geçici dosyalar yerine boruları kullanmak daha kullanışlı çünkü:
• Kabuk ifadesi çok daha kısa ve basit.
• Sonradan silinişi gereken geçici alışılagelmiş dosyalar yaratmağa ihtiyaç yok.
18.1.1 Using a Pipe
Borular bindirilmiş (mounted) dosya sistemlerinde ilgili hiçbir görüntüsü (image) olmayan
açık dosyalar olarak değerlendirilebilir. Yeni bir boru, bir çift dosya tanımlayıcıyı (file descriptor) geri döndüren boru() (pipe( ) ) sistem çağrısı ile yaratılabilir. Süreç birinci dosya tanımlayıcı ile oku() (read( )) sistem çağrısını kullanarak borudan okuyabilir; benzer şekilde, ikinci dosya tanımlayıcı ile boru() (pipe( ) ) sistem çağrısını kullanarak boruya yazabilir.
POSIX yalnız yarı-karşılıklı (half-duplex) boruları tanımlar, bu yüzden boru() (pipe( ) ) sistem çağrısı iki dosya tanımlayıcıyı geri döndürse bile, her süreç kullanmadan önce bunlardan birini kapatmalıdır. Eğer iki yönlü veri akışı gerekiyorsa, süreçler boru() (pipe( ) ) ‘yu iki defa başlatarak iki farklı boru kullanmalılar.
Sistem V Sürüm 4 gibi, çok sayıda Unix sistemi, tam-çift-yönlü borular gerçekleştirirler ve her iki tanımlayıcının da içine yazılışına ya da okunuşuna izin verirler.
Linux bir başka yaklaşımı benimser: herbir borunun dosya tanımlayıcıları hala tek-yönlüdür, fakat diğerini kullanmadan önce birini kapamak gerekli değildir
Geçtiğimiz örneği kaldığımız yerden ele alalım: komut kabuğu lsmore ifadesini yorumladığında, esas olarak aşağıdaki faaliyetleri yapar:
1. boru() (pipe( ) ) sistem çağrısını çalıştırır; boru() ‘nun 3 nolu dosya tanımlayıcısı(borunun okuyucu kanalı (read channel)) ve 4 noluyu (yazıcı kanalı) döndürdüğünü kabul edelim.
2. çatal() (fork( )) sistem çağrısını iki defa başlatır.
3. 3 ve 4 nolu dosya tanımlayıcıları serbest bırakmak için kapa() (close() ) sistem çağrısını iki defa başlatır.
ls programını çalıştırışı gereken birinci çocuk süreç aşağıdaki işlemleri icra eder:
1. dosya tanımlayıcı 4’ü dosya tanımlayıcıya kopyalamak için çiftle2(4,1) (dup2(4,1)) ‘yi başlatır. Bu andan itibaren dosya tanımlayıcı 1 borunun yazıcı kanalını belirtir.
2. Dosya tanımlayıcı 3 ve 4’ü serbest bırakmak için kapa() (close() ) sistem çağrısını iki kez başlatır.
3. /bin/ls programını çalıştırmak için çalıştırve() (execve( )) sistem çağrısını başlatır. Böyle bir program hiç yoktan(default) çıkışını dosya tanımlayıcı 1’e sahip olan dosyaya yazar (standart çıkış), yani, boruya yazar.
İkinci çocuk süreç more programını çalıştırmak zorunda; buyüzden, aşağıdaki işlemleri icra eder:
1. Dosya tanımlayıcı 3’ü dosya tanımlayıcı 0’a kopyalamak için çiftle2(3,0) (dup2(3,0)) ‘ü başlatır. Bu andan itibaren, dosya tanımlayıcı boru’nun okuyucu kanalını belirtir.
2. Dosya tanımlayıcı 3 ve 4’ü serbest bırakmak için kapa() (close() ) sistem çağrısını iki kez başlatır.
3. /bin/more ‘u çalıştırmak için çalıştırve() (execve( )) sistem çağrısını başlatır. Hiç yoktan, program girişini dosya tanımlayıcıya(standart giriş) sahip olan dosyadan okur; yani, borudan okur.
Bu basit örnekte, boru yalnızca iki süreç tarafından kullanıldı. Gerçekleştiriliş şeklinden dolayı, bir boru istenen sayıda süreç tarafından kullanılabilir. Açıkçası, eğer iki veya daha çok süreç aynı boruya yazar veya okursalar, erişimlerini açık ve doğrudan bir şekilde (explicitly) dosya kilitleyerek (file locking) eşzamanlı kılmalıdırlar veya süreçler arası iletişim (IPC) semaforları kullanmalıdırlar…
Çok sayıda Unix sistemi, boru() (pipe())sistem çağrısından başka, boruları kullanırken genellikle yapılan bütün kirli işleri becermek için kullanılan, paç() (popen( )) ve pkapa (pclose( )) adı verilen iki paketleyici (wrapper) fonksiyon kullanırlar. paç() (popen( )) fonksiyonunu kullanarak bir boru bir kere yaratıldı mı C kütüphanesine dahil edilmiş (fprintf( ), fscanf( ), ve diğer) üst seviye G/Ç fonksiyonları (the high-level I/O functions) ile birlikte kullanılabilirler.
Linux’ta paç() (popen( )) ve pkapa (pclose( )) C kütüphanesine dahil edilmiştir. paç() (popen( )) fonksiyonu iki başlangıç değişkeni(parameter) alır: çalıştırılabilir bir dosyanın dosyaisimi (filename) patika-ismi ve veri naklinin yönünü belirleyen bir tip (type) karakter zinciri. Bir DOSYA (FILE) veri yapısına işaret-ediciyi geri döndürür. paç() (popen( )) fonksiyonu esas olarak aşağıdaki işlemleri icra eder:
1. boru() (pipe())sistem çağrısını kullanarak yeni bir boru yaratır.
2. Kendine sıra gelince aşağıdaki işlemleri çalıştıran, yeni bir süreç çatallar(fork).
a. Eğer tip r ise, borunun yazıcı kanalı ile dosya tanımlayıcı 1 (standart çıkış) olarak ilişkilendirilen dosya tanımlayıcıyı çiftler; aksi takdirde, eğer tip w ise, borunun okuyucu kanalı ile dosya tanımlayıcı (standart giriş) olarak ilişkilendirilen dosya tanımlayıcıyı çiftler.
b. boru() (pipe()) tarafından geri döndürülen dosya tanımlayıcıları kapatır.
c. filename tarafından belirlenen programı çalıştırmak için çalıştırve() (execve( )) sistem çağrısını başlatır.
3. Eğer tip r ise, borunun yazıcı kanalı ile ilişkili dosya tanımlayıcıyı kapatır; aksi takdirde, eğer tip w ise, borunun okuyucu kanalı ile ilişkili dosya tanımlayıcıyı kapatır.
4. Boru için hangi dosya tanımlayıcı açık ise onu belirten DOSYA (FILE) dosya işaret-edicisinin adresini geri döndürür.
paç() (popen( )) başlatılışından sonra, ebeveyn ve çocuk boru içinden bilgi değiş-tokuşu yapabilirler: ebeveyn fonksiyon tarafından geri döndürülen DOSYA (FILE) işaret-edicisini kullanarak verileri ( tip r ise) okuyabilir veya (tip w ise) yazabilir. Veri çocuk süreç tarafından çalıştırılan program tarafından standart çıkışa yazılır ya da standart girişten okunur.
paç() (popen( )) tarafından geri-döndürülen dosya işaret-edicisini alan pkapa (pclose( )) fonksiyonu, yalnızca bekle4() (wait4( )) sistem çağrısını başlatır ve paç() (popen( )) tarafından yaratılmış sürecin sona erişini bekler.
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
18.1 Borular (Pipes)
Borular Unix’in bütün tat-türlerinde (flavor) bulunan bir süreçler arası iletişim mekanizmasıdır. Bir boru süreçler arasında tek yönlü veri akışıdır: bir süreç tarafından boruya yazılan verinin tamamı onu okuyan başka bir sürece çekirdek tarafından yönlendirilir.
Unix komut kabuklarında, borular operatörü ile yaratılır. Örneğin, aşağıdaki ifade kabuğa bir boru ile bağlı iki süreç yaratmağı emreder:
$ ls more
ls programını çalıştıran, birinci sürecin standart çıkışı boruya yönlendirilir; more programını çalıştıran ikinci süreç girdisini borudan okur. Aynı sonuçların iki ayrı komutu çalıştırarak elde edilebileceğini aklınızda tutunuz:
$ ls > temp
$ more < temp
İlk komut ls’in çıktısını alışılagelmiş bir dosyaya yöneltir; daha sonra ikinci komut more ‘u girişini aynı dosyadan okumağa zorlar. Tabii ki, geçici dosyalar yerine boruları kullanmak daha kullanışlı çünkü:
• Kabuk ifadesi çok daha kısa ve basit.
• Sonradan silinişi gereken geçici alışılagelmiş dosyalar yaratmağa ihtiyaç yok.
18.1.1 Using a Pipe
Borular bindirilmiş (mounted) dosya sistemlerinde ilgili hiçbir görüntüsü (image) olmayan
açık dosyalar olarak değerlendirilebilir. Yeni bir boru, bir çift dosya tanımlayıcıyı (file descriptor) geri döndüren boru() (pipe( ) ) sistem çağrısı ile yaratılabilir. Süreç birinci dosya tanımlayıcı ile oku() (read( )) sistem çağrısını kullanarak borudan okuyabilir; benzer şekilde, ikinci dosya tanımlayıcı ile boru() (pipe( ) ) sistem çağrısını kullanarak boruya yazabilir.
POSIX yalnız yarı-karşılıklı (half-duplex) boruları tanımlar, bu yüzden boru() (pipe( ) ) sistem çağrısı iki dosya tanımlayıcıyı geri döndürse bile, her süreç kullanmadan önce bunlardan birini kapatmalıdır. Eğer iki yönlü veri akışı gerekiyorsa, süreçler boru() (pipe( ) ) ‘yu iki defa başlatarak iki farklı boru kullanmalılar.
Sistem V Sürüm 4 gibi, çok sayıda Unix sistemi, tam-çift-yönlü borular gerçekleştirirler ve her iki tanımlayıcının da içine yazılışına ya da okunuşuna izin verirler.
Linux bir başka yaklaşımı benimser: herbir borunun dosya tanımlayıcıları hala tek-yönlüdür, fakat diğerini kullanmadan önce birini kapamak gerekli değildir
Geçtiğimiz örneği kaldığımız yerden ele alalım: komut kabuğu lsmore ifadesini yorumladığında, esas olarak aşağıdaki faaliyetleri yapar:
1. boru() (pipe( ) ) sistem çağrısını çalıştırır; boru() ‘nun 3 nolu dosya tanımlayıcısı(borunun okuyucu kanalı (read channel)) ve 4 noluyu (yazıcı kanalı) döndürdüğünü kabul edelim.
2. çatal() (fork( )) sistem çağrısını iki defa başlatır.
3. 3 ve 4 nolu dosya tanımlayıcıları serbest bırakmak için kapa() (close() ) sistem çağrısını iki defa başlatır.
ls programını çalıştırışı gereken birinci çocuk süreç aşağıdaki işlemleri icra eder:
1. dosya tanımlayıcı 4’ü dosya tanımlayıcıya kopyalamak için çiftle2(4,1) (dup2(4,1)) ‘yi başlatır. Bu andan itibaren dosya tanımlayıcı 1 borunun yazıcı kanalını belirtir.
2. Dosya tanımlayıcı 3 ve 4’ü serbest bırakmak için kapa() (close() ) sistem çağrısını iki kez başlatır.
3. /bin/ls programını çalıştırmak için çalıştırve() (execve( )) sistem çağrısını başlatır. Böyle bir program hiç yoktan(default) çıkışını dosya tanımlayıcı 1’e sahip olan dosyaya yazar (standart çıkış), yani, boruya yazar.
İkinci çocuk süreç more programını çalıştırmak zorunda; buyüzden, aşağıdaki işlemleri icra eder:
1. Dosya tanımlayıcı 3’ü dosya tanımlayıcı 0’a kopyalamak için çiftle2(3,0) (dup2(3,0)) ‘ü başlatır. Bu andan itibaren, dosya tanımlayıcı boru’nun okuyucu kanalını belirtir.
2. Dosya tanımlayıcı 3 ve 4’ü serbest bırakmak için kapa() (close() ) sistem çağrısını iki kez başlatır.
3. /bin/more ‘u çalıştırmak için çalıştırve() (execve( )) sistem çağrısını başlatır. Hiç yoktan, program girişini dosya tanımlayıcıya(standart giriş) sahip olan dosyadan okur; yani, borudan okur.
Bu basit örnekte, boru yalnızca iki süreç tarafından kullanıldı. Gerçekleştiriliş şeklinden dolayı, bir boru istenen sayıda süreç tarafından kullanılabilir. Açıkçası, eğer iki veya daha çok süreç aynı boruya yazar veya okursalar, erişimlerini açık ve doğrudan bir şekilde (explicitly) dosya kilitleyerek (file locking) eşzamanlı kılmalıdırlar veya süreçler arası iletişim (IPC) semaforları kullanmalıdırlar…
Çok sayıda Unix sistemi, boru() (pipe())sistem çağrısından başka, boruları kullanırken genellikle yapılan bütün kirli işleri becermek için kullanılan, paç() (popen( )) ve pkapa (pclose( )) adı verilen iki paketleyici (wrapper) fonksiyon kullanırlar. paç() (popen( )) fonksiyonunu kullanarak bir boru bir kere yaratıldı mı C kütüphanesine dahil edilmiş (fprintf( ), fscanf( ), ve diğer) üst seviye G/Ç fonksiyonları (the high-level I/O functions) ile birlikte kullanılabilirler.
Linux’ta paç() (popen( )) ve pkapa (pclose( )) C kütüphanesine dahil edilmiştir. paç() (popen( )) fonksiyonu iki başlangıç değişkeni(parameter) alır: çalıştırılabilir bir dosyanın dosyaisimi (filename) patika-ismi ve veri naklinin yönünü belirleyen bir tip (type) karakter zinciri. Bir DOSYA (FILE) veri yapısına işaret-ediciyi geri döndürür. paç() (popen( )) fonksiyonu esas olarak aşağıdaki işlemleri icra eder:
1. boru() (pipe())sistem çağrısını kullanarak yeni bir boru yaratır.
2. Kendine sıra gelince aşağıdaki işlemleri çalıştıran, yeni bir süreç çatallar(fork).
a. Eğer tip r ise, borunun yazıcı kanalı ile dosya tanımlayıcı 1 (standart çıkış) olarak ilişkilendirilen dosya tanımlayıcıyı çiftler; aksi takdirde, eğer tip w ise, borunun okuyucu kanalı ile dosya tanımlayıcı (standart giriş) olarak ilişkilendirilen dosya tanımlayıcıyı çiftler.
b. boru() (pipe()) tarafından geri döndürülen dosya tanımlayıcıları kapatır.
c. filename tarafından belirlenen programı çalıştırmak için çalıştırve() (execve( )) sistem çağrısını başlatır.
3. Eğer tip r ise, borunun yazıcı kanalı ile ilişkili dosya tanımlayıcıyı kapatır; aksi takdirde, eğer tip w ise, borunun okuyucu kanalı ile ilişkili dosya tanımlayıcıyı kapatır.
4. Boru için hangi dosya tanımlayıcı açık ise onu belirten DOSYA (FILE) dosya işaret-edicisinin adresini geri döndürür.
paç() (popen( )) başlatılışından sonra, ebeveyn ve çocuk boru içinden bilgi değiş-tokuşu yapabilirler: ebeveyn fonksiyon tarafından geri döndürülen DOSYA (FILE) işaret-edicisini kullanarak verileri ( tip r ise) okuyabilir veya (tip w ise) yazabilir. Veri çocuk süreç tarafından çalıştırılan program tarafından standart çıkışa yazılır ya da standart girişten okunur.
paç() (popen( )) tarafından geri-döndürülen dosya işaret-edicisini alan pkapa (pclose( )) fonksiyonu, yalnızca bekle4() (wait4( )) sistem çağrısını başlatır ve paç() (popen( )) tarafından yaratılmış sürecin sona erişini bekler.
Thursday 3 January 2008
LINUX Çekirdeğini Anlamak – Süreçler Arası İletişim 1
Ali Rıza SARAL(1)
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
Bölüm 18. Süreç İletişimi
Kullanıcı üslubu süreçleri kendilerini eşzamanlı kılmak ve veri değiş-tokuşu için çekirdeğe dayanmak zorundadırlar
Kulllanıcı üslubu süreçleri arasında kaba bir eşzamanlılık boş bir dosya yaratıp uygun VFS sistem çağrıları kullanarak onu kilitlemek(lock) ve açmak (unlock) şeklinde sağlanabilir.
Benzer şekilde, süreçler arasında veri paylaşımı veriyi kilitlerle korunmuş geçici dosyalara koyarak elde edilebilir. Bu yaklaşım disk dosya sistemine erişim gerektirdiğinden pahalıdır. Bu yüzden, bütün Unix çekirdekleri dosya sistemi ile etkileşmeyen ama süreç iletişimini destekleyen bir sistem çağrısı kümesi içerir. Dahası, süreçlerin eşzamanlılık isteklerini çekirdeğe nasıl göndereceklerini yönlendirmek için çok sayıda paketleyici (wrapper) fonksiyon geliştirilmiş ve uygun kütüphanelere eklenmiştir.
Unix sistemlerinin ve özellikle Linux’un süreçler arası iletişim için sunduğu imkanlar aşağıdadır.
BORU ve İLKGELENİLKÇIKAR(İsimli Borular) (Pipes and FIFOs (named pipes))
Süreçler arası üretici/tüketici etkileşiminin gerçekleştirilişine en uygun olanı. Bazı süreçler boruyu veri ile doldururken diğerleri borudan veri çıkartır. Best suited to implement producer/consumer interactions among processes. Some processes fill the pipe with data while others extract data from the pipe.
Semaforlar (Semaphores)
Çekirdek semaforlarının Kullanıcı Üslubu sürümü. Represents, as the name implies, the User Mode version of the kernel semaphores.
Mesajlar (Messages)
Süreçlerin mesajların eşzamanlı olmayan şekilde (kısa veri blokları) değiştirimine izin verir.
Ortak Bellek Bölgeleri (Shared memory regions)
Süreçlerin büyük miktarlarda veriyi verimli bir şekilde paylaşmalarının gerektiği etkileşim modellerine en uygunudur.
Soketler başlangıçta uygulama programları ile ağ arayüzü arasında veri iletişimine imkan sağlamak için sunulmuşlardı. Aynı evsahibi (host) bilgisayar üzerinde yer alan süreçler arasında iletişim aracı olarak ta kullanılabilirler; X Pencereler Sisteminin grafik arayüzü, örneğin, müşteri (client) programlarının X sunucusu (server) ile veri değişimine imkan sağlamak için bir soket kullanır.
(1) Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel ‘den faydalanarak derlenmiştir.
Bölüm 18. Süreç İletişimi
Kullanıcı üslubu süreçleri kendilerini eşzamanlı kılmak ve veri değiş-tokuşu için çekirdeğe dayanmak zorundadırlar
Kulllanıcı üslubu süreçleri arasında kaba bir eşzamanlılık boş bir dosya yaratıp uygun VFS sistem çağrıları kullanarak onu kilitlemek(lock) ve açmak (unlock) şeklinde sağlanabilir.
Benzer şekilde, süreçler arasında veri paylaşımı veriyi kilitlerle korunmuş geçici dosyalara koyarak elde edilebilir. Bu yaklaşım disk dosya sistemine erişim gerektirdiğinden pahalıdır. Bu yüzden, bütün Unix çekirdekleri dosya sistemi ile etkileşmeyen ama süreç iletişimini destekleyen bir sistem çağrısı kümesi içerir. Dahası, süreçlerin eşzamanlılık isteklerini çekirdeğe nasıl göndereceklerini yönlendirmek için çok sayıda paketleyici (wrapper) fonksiyon geliştirilmiş ve uygun kütüphanelere eklenmiştir.
Unix sistemlerinin ve özellikle Linux’un süreçler arası iletişim için sunduğu imkanlar aşağıdadır.
BORU ve İLKGELENİLKÇIKAR(İsimli Borular) (Pipes and FIFOs (named pipes))
Süreçler arası üretici/tüketici etkileşiminin gerçekleştirilişine en uygun olanı. Bazı süreçler boruyu veri ile doldururken diğerleri borudan veri çıkartır. Best suited to implement producer/consumer interactions among processes. Some processes fill the pipe with data while others extract data from the pipe.
Semaforlar (Semaphores)
Çekirdek semaforlarının Kullanıcı Üslubu sürümü. Represents, as the name implies, the User Mode version of the kernel semaphores.
Mesajlar (Messages)
Süreçlerin mesajların eşzamanlı olmayan şekilde (kısa veri blokları) değiştirimine izin verir.
Ortak Bellek Bölgeleri (Shared memory regions)
Süreçlerin büyük miktarlarda veriyi verimli bir şekilde paylaşmalarının gerektiği etkileşim modellerine en uygunudur.
Soketler başlangıçta uygulama programları ile ağ arayüzü arasında veri iletişimine imkan sağlamak için sunulmuşlardı. Aynı evsahibi (host) bilgisayar üzerinde yer alan süreçler arasında iletişim aracı olarak ta kullanılabilirler; X Pencereler Sisteminin grafik arayüzü, örneğin, müşteri (client) programlarının X sunucusu (server) ile veri değişimine imkan sağlamak için bir soket kullanır.
Subscribe to:
Posts (Atom)